https://juejin.cn/post/7204707115062411320#heading-1
https://juejin.cn/post/7204707115062411320#heading-1
大纲
Html5和CSS3
常见的水平垂直居中实现方案
BFC问题
flex:1:是哪些属性的缩写,对应的属性代表什么含义
隐藏元素的属性有哪些
浏览器的事件循环机制
TypeScript
type和interfacel的区别
any、unkonwn、never
常见的工具类型
Html5和CSS3
常见的水平垂直居中实现方案
https://blog.csdn.net/m0_70705683/article/details/135777987
- 方案总结*
方案总结
利用定位(父相子绝) + 位移
-
- 父相子绝 + 子 margin:auto;
-
- 父相子绝 + 子 top,left 位移50%; transform:translate(-50%,-50%);
<style>
.father{
//width,height,其他省略
position: relative;
}
.son{
position: absolute;
top:0;
left:0;
right:0;
bottom:0;
margin:auto;
}
</style>
<div class="father">
<div class="son"></div>
</div>
利用定位+margin:负值
<style>
.father {
position: relative;
width: 200px;
height: 200px;
background: skyblue;
}
.son {
position: absolute;
top: 50%;
left: 50%;
margin-left:-50px;
margin-top:-50px;
width: 100px;
height: 100px;
background: red;
}
</style>
<div class="father">
<div class="son"></div>
</div>
table布局
<style>
.father {
//width,height,其他省略
display: table-cell;
text-align: center;//水平居中
vertical-align: middle;//垂直居中
}
.son {
//width,height,其他省略
display: inline-block;
}
</style>
<div class="father">
<div class="son"></div>
</div>
flex弹性布局
<style>
.father {
display: flex;
justify-content: center;//主轴居中,默认水平居中
align-items: center;//交叉轴居中,默认垂直居中
}
.son {
}
</style>
<div class="father">
<div class="son"></div>
</div>
grid网格布局
<style>
.father {
display: grid;
justify-content: center;//主轴居中,默认水平居中
align-items: center;//交叉轴居中,默认垂直居中
}
.son {
}
</style>
<div class="father">
<div class="son"></div>
</div>
拓展
在CSS中实现元素的水平和垂直居中布局是一个常见需求,不同的元素类型(内联元素和块级元素)和布局方法(如Flexbox、Grid、定位等)提供了多种解决方案。以下是对您提供的文件内容的总结:
内联元素居中布局
- 水平居中*:
-
行内元素可以通过设置父元素的
text-align: center;来实现水平居中。 -
使用Flexbox布局,可以设置父元素为
display: flex;并使用justify-content: center;来实现水平居中。
- 垂直居中*:
-
对于单行文本,可以通过设置父元素的高度等于行高(
height === line-height)来实现垂直居中。 -
对于多行文本,可以使用表格单元格布局,将父元素设置为
display: table-cell;并使用vertical-align: middle;来实现垂直居中。
块级元素居中布局
- 水平居中*:
-
对于已定义宽度的元素,可以通过设置
margin: 0 auto;来实现水平居中。 -
使用绝对定位,可以将元素的
left属性设置为50%,然后使用margin-left设置为元素宽度的一半的负值来实现水平居中。
- 垂直居中*:
-
使用绝对定位,可以设置元素的
top、left、margin-top和margin-left(如果已定义高度)来实现垂直居中。 -
通过设置父元素为
display: table-cell;并使用vertical-align: middle;可以实现垂直居中。 -
使用
transform: translate(x, y);可以在不知道元素宽高的情况下实现垂直居中。 -
使用Flexbox(
display: flex;)和Grid(display: grid;)也可以实现垂直居中,但Grid的兼容性相对较差。
BFC问题
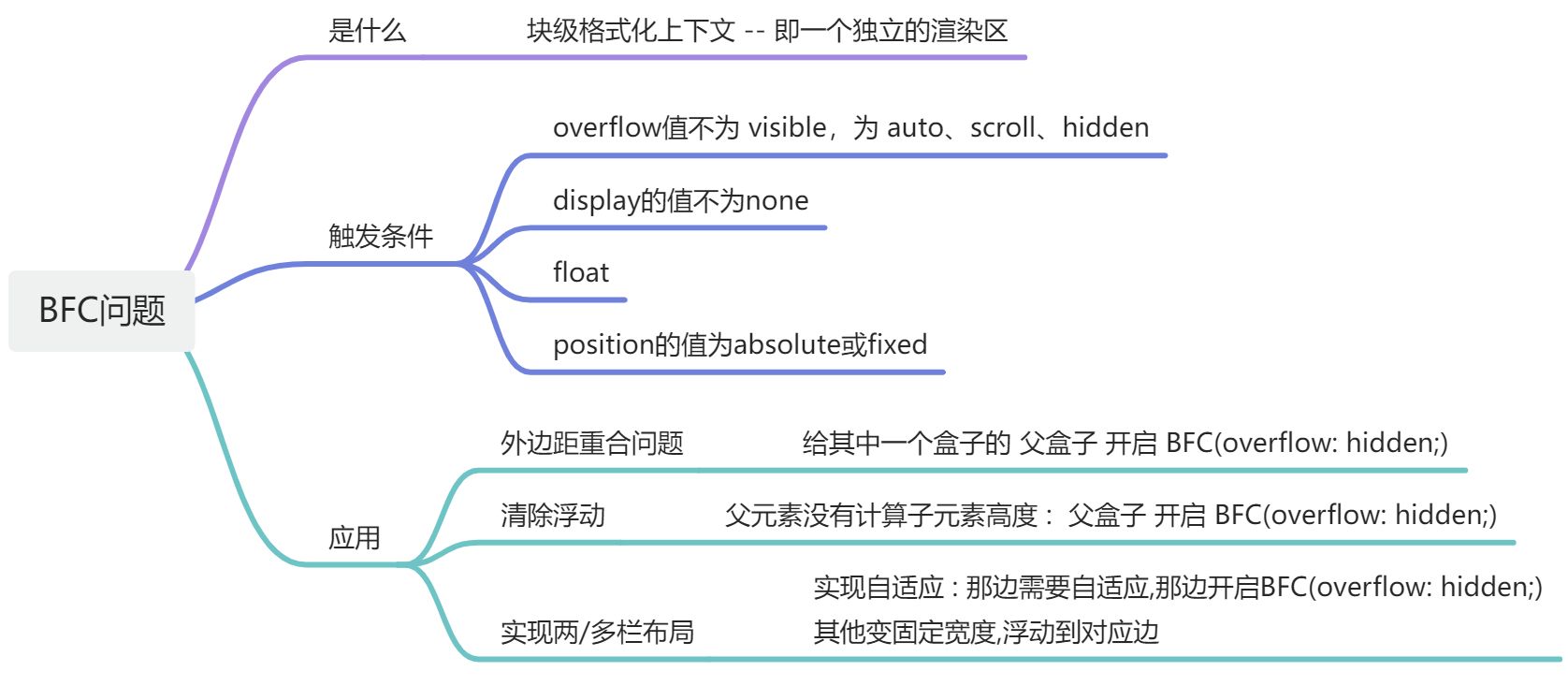
https://blog.csdn.net/qq_63299825/article/details/131048599
https://blog.csdn.net/qq_63299825/article/details/131048599
一、BFC的定义 (一个独立的渲染区)
- BFC*(Block Formatting Context),即块级格式化上下文,它是页面中的一块渲染区域,并且有一套属于自己的渲染规则,
-
内部的盒子会在垂直方向上一个接一个的放置
-
对于同一个BFC的俩个相邻的盒子的margin会发生重叠,与方向无关。
-
每个元素的左外边距与包含块的左边界相接触(从左到右),即使浮动元素也是如此
-
BFC的区域不会与float的元素区域重叠
-
计算BFC的高度时,浮动子元素也参与计算
-
BFC就是页面上的一个隔离的独立容器,容器里面的子元素不会影响到外面的元素,反之亦然
BFC目的是形成一个相对于外界完全独立的空间,让内部的子元素不会影响到外部的元素
在页面布局阶段,往往会因为BFC问题导致 页面布局发生错乱,如外边距合并问题,元素高度丢失,两栏布局没有实现自适应。
二、触发BFC的条件
-
根元素,即HTML元素
-
浮动元素:float值为left、right
-
overflow值不为 visible,为 auto、scroll、hidden
-
display的值为除了none以外的全部值, inline-block、inltable-cell、table-caption、table、inline-table、flex、inline-flex、grid、inline-grid
-
position的值为absolute或fixed
四、BFC的应用场景(https://blog.csdn.net/qq_63299825/article/details/131048599)
1.避免外边距重叠
当兄弟盒子设置 同时给兄弟元素设置一个下外边距同时设置一个上外边距,发生外边距合并
<style>
div:first-child {
width: 100px;
height: 100px;
background: red;
margin-bottom: 10px;
}
div:last-child {
width: 100px;
height: 100px;
background: green;
margin-top: 20px;
}
</style>
<div class="cube"></div>
<div class="cube"></div>
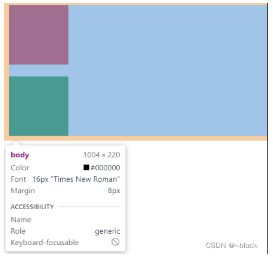
最佳方法:当我们给第一个盒子一个父盒子,并触发父盒子生成一个BFC,那么两个div就不属于同一个BFC,则不会出现外边距重叠问题。
<style>
.cube {
width: 100px;
height: 100px;
background-color: red;
margin-bottom: 10px;
}
.cube1:last-child {
width: 100px;
height: 100px;
background-color: red;
margin-top: 20px;
}
.container {
/* 开启bfc属性 */
overflow: hidden;
}
</style>
<div class="container">
<div class="cube"></div>
</div>
<div class="cube1"></div>
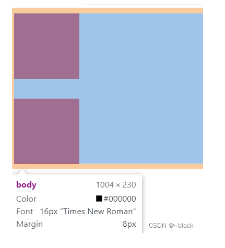
2.清除浮动
在父元素parent计算高度时,并没有计算子元素child的高度。
<style>
.parent {
border: 10px solid red;
}
.child {
width: 100px;
height: 100px;
background-color: blue;
/* 浮动效果 */
float: left;
}
</style>
<div class="parent">
<div class="child"></div>
</div>

我们给父元素生成BFC后,父元素在计算高度时就会将浮动子元素child的高度也计算到其中
.parent {
border: 10px solid red;
/* 开启bfc overflow hidden auto */
overflow: hidden;
}

3.实现两栏布局
左侧设置宽度,右边自适应,右边开启BFC
<style>
.left{
width: 300px;
background-color: red;
float: left;
}
.right{
background-color: blue;
/* 开启bfc */
overflow: hidden;
}
</style>
<div class="left">左侧定宽</div>
<div class="right">右侧自适应右侧自适应右侧自适应右侧自适应
右侧自适应右侧自适应右侧自适应右侧自适应右侧自适应右侧自适应
右侧自适应右侧自适应右侧自适应右侧自适应右侧自适应右侧自适应
右侧自适应右侧自适应右侧自适应右侧自适应右侧自适应右侧自适应
</div>
实现了两栏布局且右边是自适应

4.实现三栏布局
思路:左右两边固定宽度,给左盒子float:left;给右盒子float:right,给中间盒子开启BFC,实现左右固定宽度,中间自适应的效果
<style>
/* 三列布局 左侧右侧定宽 中间自适应 */
.left,
.right {
width: 100px;
height: 50px;
background-color: red;
}
.left {
float: left;
}
.right {
float: right;
}
.center {
height: 100px;
background-color: blue;
/* 开启bfc */
overflow: hidden;
}
</style>
<div class="left"></div>
<div class="right"></div>
<div class="center"></div>

三、外边距合并问题
.兄弟级外边距合并
合并出现原因:同时给兄弟元素设置一个下外边距同时设置一个上外边距,发生外边距合并
合并解决方案:
-
只给其中一个兄弟元素设置外边距
-
给下边外边距开启BFC
-
display:inline-blick/flex
-
position:absolute/fixed
-
float:left
-
给上边兄弟元素设置一个父元素 给父元素开启BFC
overflow hidden/auto
- 父子级外边距合并
合并出现原因:同时给父子元素设置同一方向的一个外边距
合并解决方案:
-
给父元素设置padding属性
-
给父元素设置border边框
flex:1:是哪些属性的缩写,对应的属性代表什么含义
flex:1 属性时,
代表 flex-grow: 1、flex-shirnk:1、flex-basis:0%
-
flex:1实际代表的是三个属性的简写
-
flex-grow是用来增大盒子的,比如,当父盒子的宽度大于子盒子的宽度,父盒子的剩余空间可以利用flex-grow来设置子盒子增大的占比
-
flex-shrink用来设置子盒子超过父盒子的宽度后,超出部分进行缩小的取值比例
-
flex-basis是用来设置盒子的基准宽度,并且basis和width同时存在basis会把width干掉
所以flex:1;的逻辑就是用flex-basis把width干掉,然后再用flex-grow和flex-shrink增大的增大缩小的缩小,达成最终的效果。
flex-basis:指定元素在主轴的大小,可以等同width或者height,优先级要高于width和height
https://www.cnblogs.com/mmzuo-798/p/17246920.html
https://www.cnblogs.com/mmzuo-798/p/17246920.html
隐藏元素 的属性有哪些
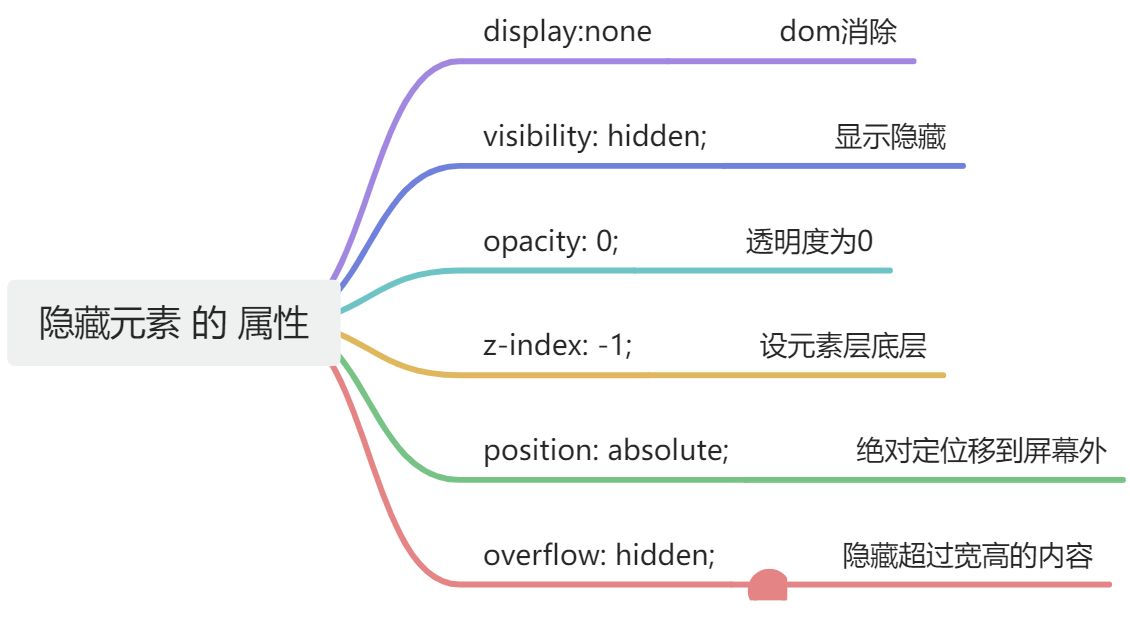
在CSS中,隐藏元素可以通过多种方式实现,每种方式都有其特定的用途和效果。以下是一些常用的方法来隐藏元素:
display: none;:
-
完全从文档流中移除元素,不占据任何空间。
-
元素不会被显示,也不会影响到其他元素的布局。
visibility: hidden;:
-
元素在页面上不可见,但它仍占据着原来的空间。
-
与
display: none;不同,使用visibility: hidden;隐藏的元素仍会影响布局,因为它仍占据空间。
opacity: 0;:
-
将元素的透明度设置为0,使其完全透明,从而看不见。
-
元素仍然占据空间,并且可以响应交互(如点击)。
z-index: -1;:
-
通过将
z-index属性设置为负值,可以使元素被其他元素覆盖,从而在视觉上“隐藏”。 -
元素仍然可见,如果页面上没有其他元素覆盖它,或者在某些情况下,它可能会重新可见。
position: absolute;与left/top属性结合:
-
将元素通过绝对定位移出视口外,例如设置
left: -9999px;或top: -9999px;。 -
元素不可见,但仍然占据空间。
clip-path: inset(100%);或clip: rect(0, 0, 0, 0);:
-
使用
clip-path或clip属性将元素的可视区域设置为0,从而在视觉上隐藏元素。 -
元素不可见,且不占据空间。
height: 0; width: 0;:
-
将元素的宽度和高度设置为0,使其不可见。
-
元素不可见,且不占据空间,除非有边框或内边距。
overflow: hidden;:
-
当与
height或width属性结合使用时,可以隐藏元素内溢出的内容。 -
元素本身仍然可见,但超出部分的内容不可见。
- 使用
aria-hidden="true"属性:
-
这是一个无障碍性(accessibility)相关的属性,用于告知辅助技术(如屏幕阅读器)忽略该元素。
-
元素在视觉上仍然可见,但不会传达给使用辅助技术的用户。
pointer-events: none;:
-
禁止元素响应指针事件,如点击、悬停等。
-
元素在视觉上仍然可见,但用户无法与之交互。
选择哪种方法取决于你的具体需求,比如是否需要元素继续参与文档流的布局,是否需要保持可访问性,或者是否需要元素在某些情况下重新可见。
Js相关
Js相关
Js的基础类型,typeof和instanceof的区别
数组的forEach和map方法有哪些区别?常用哪些方法去对数组进行增、删、改
闭包和作用域
实现一个类以关键字new功能的函数
如何实现继承(原型和原型链)
箭头函数和普通函数有什么区别
迭代器(iterator)接口和生成器(generator)函数的关系
浏览器的事件循环机制
js 类型判断
https://blog.csdn.net/mywpython/article/details/134671186
https://blog.csdn.net/mywpython/article/details/134671186

- Object.prototype.toString.call*
Object.prototype.toString.call方法返回各数据类型的[object xxx]形式:
去掉Object.prototype.toString.call方法返回结果中的"[object",只保留具体类型:
function getType(data) {
return Object.prototype.toString.call(data).replace(/[object\s+(.+)]/, '$1' ).toLowerCase()
}
- 四、Object.prototype.toString.call*
Object.prototype.toString.call方法返回各数据类型的[object xxx]形式:
const str = 'testme'
Object.prototype.toString.call(str) // [object String]
const num = 123
Object.prototype.toString.call(num) // [object Number]
const bol = true
Object.prototype.toString.call(bol) // [object Boolean]
const sy = Symbol('a')
Object.prototype.toString.call(sy) // [object Symbol]
const bi = BigInt("12345678910111213")
Object.prototype.toString.call(bi) // [object BigInt]
Object.prototype.toString.call(null) // [object Null]
Object.prototype.toString.call(undefined) // [object Undefined]
const arr = [1,5,7]
Object.prototype.toString.call(arr) // [object Array]
const obj = {a:3}
Object.prototype.toString.call(obj) // [object Object]
function Man(name,age) {
this.name = name
this.age = age
}
Object.prototype.toString.call(Man) // [object Function]
const man = new Man('Lily', 12)
Object.prototype.toString.call(man) // [object Object]
1. 使用typeof判断基本类型:
const str = 'testme'
typeof str // string
const num = 123
typeof num // number
const bol = true
typeof bol // boolean
const nu = null
type nu // object
typeof undefVar // undefined
const sy = Symbol('a')
typeof sy // symbol
const bi = BigInt("12345678910111213")
typeof bi // bigint
2. 使用typeof判断引用类型:
const arr = [1,5,7]
typeof arr // object
const obj = {a:3}
typeof obj // object
function Man(name,age) {
this.name = name
this.age = age
}
typeof Man // function
const man = new Man('Lily', 12)
typeof man // object
- 二、instanceof*
使用方法: A instanceof B
const arr = [1,5,7]
arr instanceof Array // true
const obj = {a:3}
obj instanceof Object // true
obj instanceof Array // false
function Man(name,age) {
this.name = name
this.age = age
}
Man instanceof Function // true
const man = new Man('Lily', 12)
man instanceof Object // true
- 三、constructor*
const str = 'testme'
str.constructor === String // true
const num = 123
num.constructor === Number // true
const bol = true
bol.constructor === Boolean // true
const arr = [1,5,7]
arr.constructor === Array // true
const obj = {a:3}
obj.constructor === Object // true
function Man(name,age) {
this.name = name
this.age = age
}
Man.constructor === Function // true
const man = new Man('Lily', 12)
man.constructor === Man // true
但是像 null、undefined这种就调用不了constructor判断数据类型了
怎么判断两个对象相等?
https://juejin.cn/post/7408226845466902568
总结
判断两个对象是否相等可以通过以下几种主要方式:
-
引用比较:使用
===操作符,仅适用于比较对象引用。 -
JSON 字符串化:通过
JSON.stringify()方法比较对象的字符串表示,适用于简单对象。 -
深度比较:递归地比较对象的属性,适用于复杂对象。
-
使用第三方库:如 Lodash 或其他深度比较库,处理各种复杂的比较需求。_.isEqual(obj1, obj2)
判断两个对象相等
在JavaScript中,判断两个对象是否相等或者判断一个对象是否为空,涉及到几个不同的概念和方法。
JavaScript中的对象是引用类型,这意味着当你比较两个对象时,即使它们包含相同的数据,它们也是不相等的,因为它们在内存中的地址不同。以下是一些判断对象相等的方法:
- 严格等于(
===):这会检查两个对象是否是同一个引用,如果不是同一个引用,则返回false。
const obj1 = { a: 1 };
const obj2 = { a: 1 };
console.log(obj1 === obj2); // 输出 false
- JSON.stringify():将对象转换为JSON字符串,然后比较字符串是否相同。这种方法适用于简单对象,但对于包含函数、循环引用或特殊对象(如
Date)的对象不适用。
const obj1 = { a: 1 };
const obj2 = { a: 1 };
console.log(JSON.stringify(obj1) === JSON.stringify(obj2)); // 输出 true
- 使用库:有一些库如lodash提供了深度比较功能,可以比较两个对象的内容是否相等。
import _ from 'lodash';
const obj1 = { a: 1 };
const obj2 = { a: 1 };
console.log(_.isEqual(obj1, obj2)); // 输出 true
如何判断空对象?
-
总结*
-
*包含可枚举 和 不可枚举 **
-
Reflect.ownKeys() ( 强烈推荐) :返回一个数组,包含对象自身的所有属性键*(包含symbol),包括不可枚举的属性和符号属性。
Object.keys(obj).length === 0 // 输出 true
- Object.getOwnPropertyNames: 方法返回一个数组,包含对象自身的所有属性名*,不管它们是否可枚举。
Object.getOwnPropertyNames(obj).length === 0 // 输出 true
-
可枚举*
-
JSON.stringify(obj) === '{}'*
-
Object.keys(obj).length === 0*
-
Object.entries(obj).length === 0*
-
for...in循环*
判断空对象
Object.getOwnPropertyNames()或者Reflect.ownKeys()。
Object.getOwnPropertyNames() 和 Reflect.ownKeys() 是 JavaScript 中用于获取对象自身属性的方法,包括不可枚举的属性和符号属性。这两个方法都可以帮助你判断一个对象是否为空,但它们有一些区别。
Object.getOwnPropertyNames()
Object.getOwnPropertyNames() 方法返回一个数组,包含对象自身的所有属性名,不管它们是否可枚举。
const obj = { a: 1 };
Object.defineProperty(obj, 'b', {
value: 2,
enumerable: false
});
console.log(Object.getOwnPropertyNames(obj)); // 输出 ["a", "b"]
在这个例子中,"b" 属性是不可枚举的,但 Object.getOwnPropertyNames() 仍然能够获取到它。
Reflect.ownKeys()
Reflect.ownKeys() 方法返回一个数组,包含对象自身的所有属性键,包括不可枚举的属性和符号属性。
const obj = { a: 1 };
Object.defineProperty(obj, 'b', {
value: 2,
enumerable: false
});
const symbol = Symbol('c');
obj[symbol] = 3;
console.log(Reflect.ownKeys(obj)); // 输出 ["a", "b", Symbol(c)]
在这个例子中,Reflect.ownKeys() 不仅获取了不可枚举的属性 "b",还获取了符号属性 Symbol(c)。
要判断一个对象是否为空,你可以使用这两个方法中的任何一个来获取对象的所有自身属性键,然后检查返回的数组是否为空。
const obj = {};
// 使用 Object.getOwnPropertyNames()
console.log(Object.getOwnPropertyNames(obj).length === 0); // 输出 true
// 使用 Reflect.ownKeys()
console.log(Reflect.ownKeys(obj).length === 0); // 输出 true
在这两个例子中,如果对象 obj 没有任何自身的属性,那么这两个方法都会返回一个空数组,数组的长度为0,表示对象为空。
总结
-
Object.getOwnPropertyNames():返回对象自身的所有属性名,包括不可枚举的属性。 -
Reflect.ownKeys():返回对象自身的所有属性键,包括不可枚举的属性和符号属性。
在大多数情况下,Reflect.ownKeys() 提供了更全面的结果,因为它还包括了符号属性。如果你只需要获取字符串属性名,那么 Object.getOwnPropertyNames() 就足够了。在选择使用哪个方法时,需要根据你的具体需求来决定。
判断空对象
空对象指的是一个对象没有任何可枚举的属性。以下是一些判断对象是否为空的方法:
- for...in循环:使用
for...in循环遍历对象的属性,如果没有属性执行,那么对象为空。
const obj = {};
for (let key in obj) {
if (obj.hasOwnProperty(key)) {
console.log('Object is not empty');
return;
}
}
console.log('Object is empty');
- Object.keys():这个方法返回一个包含对象所有自身可枚举属性的数组,如果数组长度为0,则对象为空。
const obj = {};
console.log(Object.keys(obj).length === 0); // 输出 true
- JSON.stringify():将对象转换为JSON字符串,空对象转换后的结果是一个空的大括号
{}。
const obj = {};
console.log(JSON.stringify(obj) === '{}'); // 输出 true
- Object.entries():这个方法返回一个给定对象自身可枚举属性的键值对数组,如果数组长度为0,则对象为空。
const obj = {};
console.log(Object.entries(obj).length === 0); // 输出 true
请注意,这些方法只能检测对象是否有可枚举的属性,它们不会检查对象的原型链上的属性。如果需要检查对象是否完全没有属性(包括不可枚举的属性和原型链上的属性),可以使用Object.getOwnPropertyNames()或者Reflect.ownKeys()。
数组的forEach和map方法有哪些区别?常用哪些方法去对数组进行增、删、改
拓展
forEach 和 map 是JavaScript中用于数组遍历和元素处理的两个常用方法,它们有一些关键的区别:
forEach 方法
-
forEach方法会对数组的每个元素执行一次提供的函数。 -
它不返回任何值,即返回
undefined。 -
它不能被中断,即使在回调函数中抛出错误,
forEach也会继续执行直到数组的末尾。 -
它常用于执行副作用操作,如数组的遍历、累加求和等。
let numbers = [1, 2, 3];
numbers.forEach(function(number) {
console.log(number); // 输出每个元素
});
map 方法
-
map方法也遍历数组的每个元素,但会返回一个新数组,新数组的元素是原数组元素经过回调函数处理后的结果。 -
它不会更改原数组,而是创建一个新数组。
-
它可以通过返回值进行链式调用。
-
它常用于对数组中的每个元素进行转换或计算,并获取一个新的数组。
let numbers = [1, 2, 3];
let squares = numbers.map(function(number) {
return number * number; // 返回每个元素的平方
});
console.log(squares); // 输出 [1, 4, 9]
增删改方法
对于数组的增、删、改操作,JavaScript 提供了多种方法:
- 增加元素:*
-
push(...items):在数组末尾添加一个或多个元素,并返回新的长度。 -
unshift(...items):在数组开头添加一个或多个元素,并返回新的长度。 -
splice(index, 0, ...items):在指定位置添加元素。
- 删除元素:*
-
pop():删除数组的最后一个元素,并返回被删除的元素。 -
shift():删除数组的第一个元素,并返回被删除的元素。 -
splice(index, count):删除指定位置的元素。 -
filter(callback):创建一个新数组,包含通过测试的所有元素。
- 修改元素:*
-
splice(index, count, ...items):删除指定位置的元素,并可在该位置添加新元素。 -
slice()结合concat()或push():创建一个数组的副本,然后添加或修改元素。 -
map(callback):创建一个新数组,其元素是原数组元素经过回调函数处理后的结果。
- 其他常用方法:*
-
concat(...items):创建一个新数组,包含原数组的元素和/或额外的参数。 -
slice(start, end):提取原数组的一部分,返回一个新数组。 -
reduce(callback, initialValue):将数组中的值通过回调函数处理后缩减为单一的返回值。 -
find(callback):返回数组中满足提供的测试函数的第一个元素的值。 -
some(callback):检测数组中至少有一个元素通过测试。 -
every(callback):检测数组的所有元素是否都通过了测试。
选择哪种方法取决于你的具体需求,比如是否需要修改原数组、是否需要返回新数组、是否需要执行复杂的条件检查等。
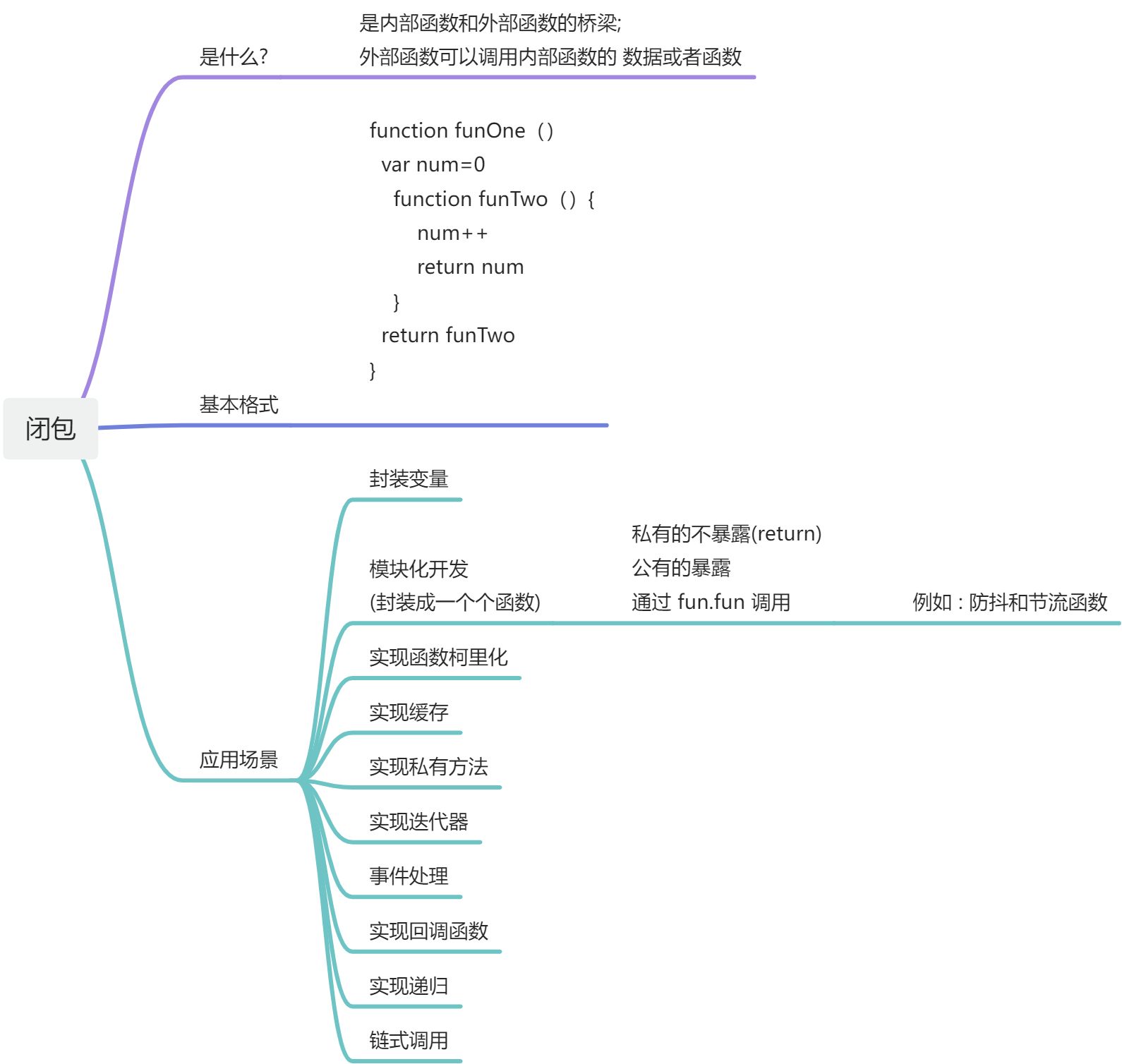
闭包和作用域
- *把闭包简单理解成“定义在一个函数内部的函数”**。
https://blog.csdn.net/Ed7zgeE9X/article/details/133819940
https://blog.csdn.net/Ed7zgeE9X/article/details/133819940
实现一个类以关键字new功能的函数
- 相当于创建一个 空对象,并将其 原型 指向 其构造函数 ;空对象 赋值 构造函数 this 然后返回对象*
在js中new关键字主要做了:
首先创建一个空对象,这个对象会作为执行new构造函数之后返回的对象实例,
将创建的空对象原型(proto)指向构造函数的prototype属性,
同时将这个空对象赋值给构造函数内部的this,并执行构造函数逻辑,
根据构造函数的执行逻辑,返回初始创建的对象或构造函数的显式返回值。
function newFn(...args) {
const constructor = args.shift();
const obj = Object.create(constructor.prototype);
const result = constructor.apply(obj, args);
return typeof result === "object" && result !== null ? result : obj;
}
function Person(name) {
this.name = name;
}
const p = newFn(Person, "Jerome");
console.log("p.name :>> ", p.name); // p.name :>> Jerome
在编程中,“关键字new功能”通常指的是使用new关键字来创建一个类的新实例。下面我将提供一个简单的示例,展示如何在JavaScript中实现一个类,并使用new关键字来创建其实例。
// 定义一个类
class Person {
// 构造函数,用于初始化实例
constructor(name, age) {
this.name = name; // 实例的name属性
this.age = age; // 实例的age属性
}
// 实例方法,可以被所有实例调用
greet() {
console.log(`Hello, my name is ${this.name} and I am ${this.age} years old.`);
}
}
// 使用new关键字创建Person类的实例
let person1 = new Person('Alice', 30);
// 调用实例方法
person1.greet(); // 输出: Hello, my name is Alice and I am 30 years old.
在这个例子中,Person是一个类,它有一个构造函数constructor,用于初始化实例的属性(name和age)。greet是一个实例方法,可以通过创建的实例调用。
当你使用new Person('Alice', 30)时,你实际上是在创建一个新的Person对象,并且调用了它的构造函数来初始化属性。之后,你可以使用这个新创建的对象来调用它的方法,比如person1.greet()。
如果你需要在其他编程语言中实现类似的功能,请告诉我具体的语言,我可以提供相应的示例。
https://blog.csdn.net/qq_17335549/article/details/138100619
如何实现继承(原型和原型链)
https://blog.csdn.net/qq_17335549/article/details/138100619
https://blog.csdn.net/qq_17335549/article/details/138100619
- 使用class语法,用extends进行继承, 或 直接改变对象的__proto__指向。*
总结
总之关于原型这块记住三句话
-
对象有一个内置属性 [[Prototype]],使用 Object.getPrototypeOf(obj) 获取
-
函数有一个公开可访问不可枚举属性 prototype
-
函数的 prototype 属性有一个公开可访问的不可枚举属性 constructor,指向函数本身
2.4 原型相关的面试题目
2.4.1 说说你对原型和原型链的理解
回答问题分文两步
(1)原型/原型链是什么?【引用上面的三句话即可】
在 js 中每个对象都有一个内置属性 [[prototype]],可以使用 Object.getPrototypeOf 来获取,指向一个对象;同样的,这个指向的对象也有内置属性[[prototype]] 这样就构成了原型链,原型链最终会指向 Object.prototype,而 Object.prototype 的内置属性 [[prototype]] 指向 null.
同时函数都有一个公开可访问属性 prototype,这个 prototype 属性又有一个 constructor 属性指向函数本身。
(2)原型链有什么用?【属性查找、继承、扩展、属性和方法的共享】
当访问对象的一个属性的时候,如果自身没有找到,就会去原型链上查找,直到找到该属性,或者遍历完完整的原型链,也就是说可以使用原型链实现继承功能。对象可以通过原型链继承父对象的属性或者方法【继承】
也可以使用原型链对对象进行扩展,通过修改原型对象,可以给所有的实例进行属性的增加或修改。如果我们在一个对象的原型上添加属性或者方法,所有基于该原型的实例都会自动继承这些属性和方法,这样可以在不修改每个实例的情况下,实现对对象的扩展【扩展】【注意这一点也是原型链继承的弊端】【也是实例之间属性和方法的共享的方法】
六、寄生式组合继承【必会】
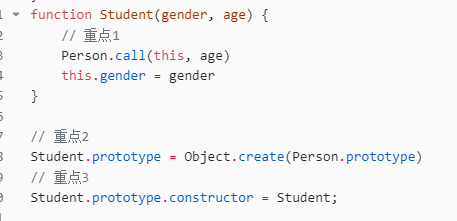
我不喜欢这个名字,因为他听起来很高端的样子,还不如叫 es5 继承终极版!
很简单,把 new Person() 换成 Object.create(Person.prototype)就行了。
function Person(age) {
this.name = 'mike';
this.age = {
num: age
}
}
Person.prototype.getName = function() {
return this.name;
}
function Student(gender, age) {
// 重点1
Person.call(this, age)
this.gender = gender
}
// 重点2
Student.prototype = Object.create(Person.prototype)
// 重点3
Student.prototype.constructor = Student;
const student = new Student('man', 12);
const student1 = new Student('women', 25)
console.log(Object.getPrototypeOf(student))
// 修改第一个实例
student.age.num = 3
console.log('第一个学生', student.age, student.getName())
console.log('第二个学生', student1.age, student1.getName())
这里面其实应用到了,Object.create 的原理,这也是一个面试题目,而且也有可能让你手写一个 Object.create 请看这篇文章。
小结
好吧,整半天就一套代码,如果面试官让你写 es5 的继承,你直接上来就终极版代码安排,我想他应该没有什么可问的了吧,所以你别看概念上那么继承方式那么多,但是实际应用就是一个!一定要记住,可别再翻车了。
那么还有最后一个问题就是 es6 中的继承了!
七、es6 继承
7.1 代码实现
使用类 class + extends 实现继承。主要还是学会使用class 类的各种语法,有几个关键点
class 中只能有一个构造函数 constructor
可以使用 static 定义静态属性和方法,直接使用类名调用
子类使用 extends 关键字继承父类,且只能继承一个【说明 es6 原生也不支持多重继承】
子类在构造函数 constructor 中使用 super 来调用父类的构造函数,并且可以传递参数
子类中的方法和父类的同名,会覆盖父类的方法
必须使用 new 操作符,创建 class 示例
class Person {
// 定义属性
lang = 'zh'
// 定义静态属性
static nation = 'china'
// 构造函数
constructor(age) {
this.name = 'mike'
this.age = {
num: age
}
}
// 定义方法
getName() {
return this.name
}
// 定义静态方法
static getDes () {
return 'hello word'
}
}
class Student extends Person {
constructor(gender, age) {
super(age)
this.gender = gender
}
}
const student = new Student('man', 12)
const student1 = new Student('women', 25)
student.age.num = 234
console.log('静态属性方法',Person.nation, Person.getDes())
console.log('第一个学生', student.lang, student.getName())
console.log('第二个学生', student1, student.getName())
- 2 面试题目
这个时候肯定会问 es5 中的类和 es6 中的类的区别了,用自己的话总结一些这篇文章的内容即可。
- 2.1 es5 中类 es6 中的继承有什么区别
注意 es6 的class 有一个私有属性和方法,以#开头的,这个倒是不常用。
- 2.2 ts 中的类和 es6 中的类有什么区别
ts 中有类型检查
ts 有访问描述符 private 、public 、protected 等,js 中只有 #开头描述的私有属性
ts 中有抽象类和方法的概念
抽象类可以包含抽象方法,而接口只能定义方法的签名
ts 支持范型
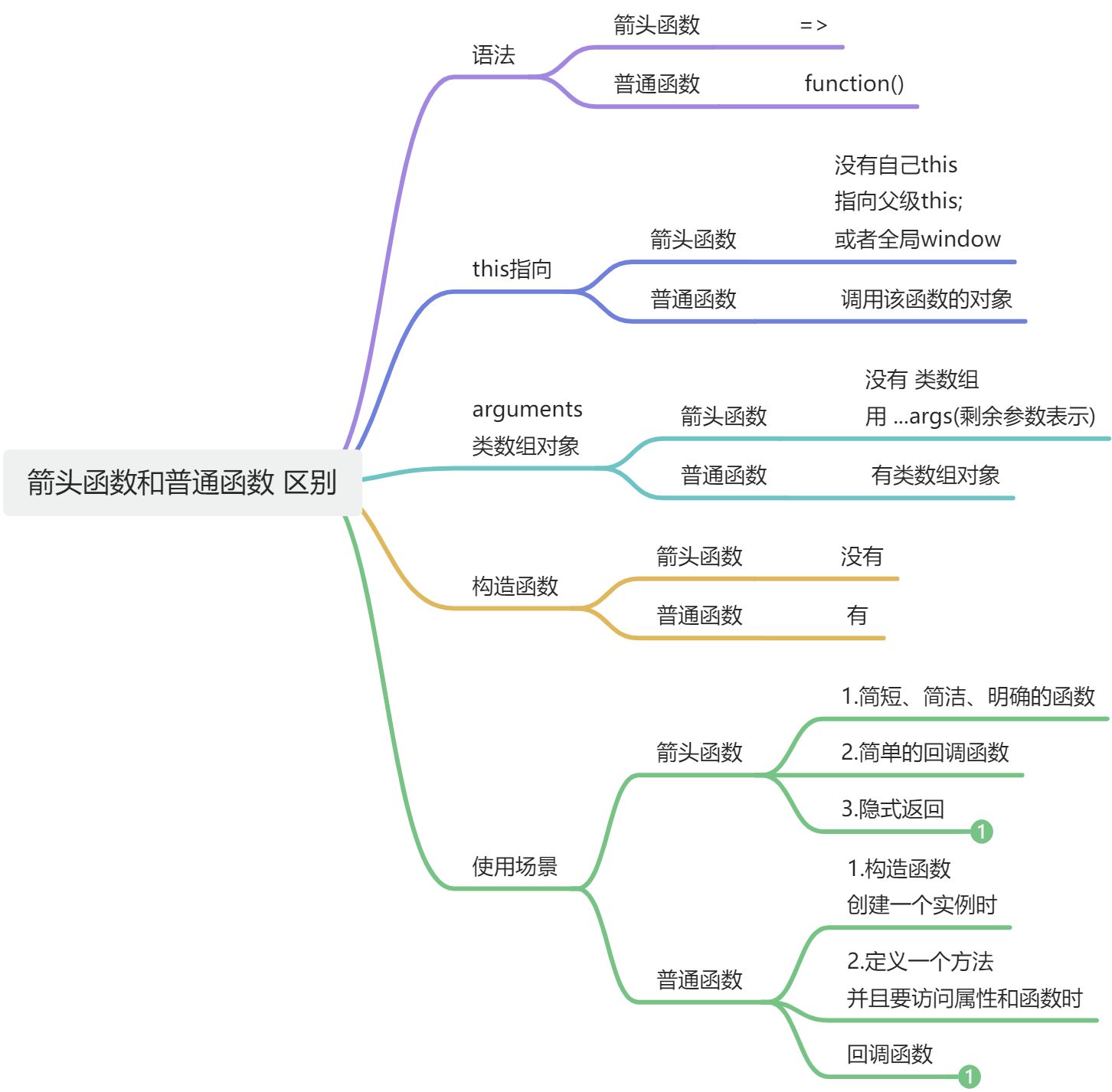
箭头函数和普通函数有什么区别
箭头函数不会创建自身的this,只会从上一级继承this,箭头函数的this在定义的时候就已经确认了,之后不会改变。
同时箭头函数无法作为构造函数使用,
没有自身的prototype,
也没有arguments。
https://blog.csdn.net/weixin_46098577/article/details/131005395
https://blog.csdn.net/weixin_46098577/article/details/131005395

迭代器(iterator)接口和生成器(generator)函数的关系
任意一个对象实现了遵守迭代器协议的[Symbol.iterator]方法,那么该对象就可以调用[Symbol.iterator]返回一个遍历器对象。
生成器函数就是遍历器生成函数,故可以把generator赋值给对象的[Symbol.iterator]属性,从而使该对象具有迭代器接口。
class ClassRoom {
constructor(address, name, students) {
this.address = address;
this.name = name;
this.students = students;
}
entry(student) {
this.students.push(student);
}
* [Symbol.iterator]() {
yield* this.students;
}
// [Symbol.iterator]() {
// let index = 0;
// return {
// next: () => {
// if (index < this.students.length) {
// return { done: false, value: this.students[index++] };
// } else {
// return { done: true, value: undefined };
// }
// },
// return: () => {
// console.log("iterator has early termination");
// return { done: true, value: undefined };
// },
// };
// }
}
const classOne = new ClassRoom("7-101", "teach-one-room", ["rose", "jack", "lily", "james"]);
for (const stu of classOne) {
console.log("stu :>> ", stu);
// stu :>> rose
// stu :>> jack
// stu :>> lily
// stu :>> james
// if (stu === "lily") return;
}
浏览器的事件循环机制
先进行宏任务(script)内的内容;
再去执行微任务队列{
-
-消息队列有优先级 :按照任务类型分(chrome浏览器中)
-
-微队列 [最高] promise.then方法
-
-交互队列 [高] 点击操作等
-
-延时队列 [中] 延时,循环延时}
然后执行微任务如果有嵌套看先执行宏任务在再按照优先级执行微任务
列举宿主对象、内置对象、原生对象并说明其定义
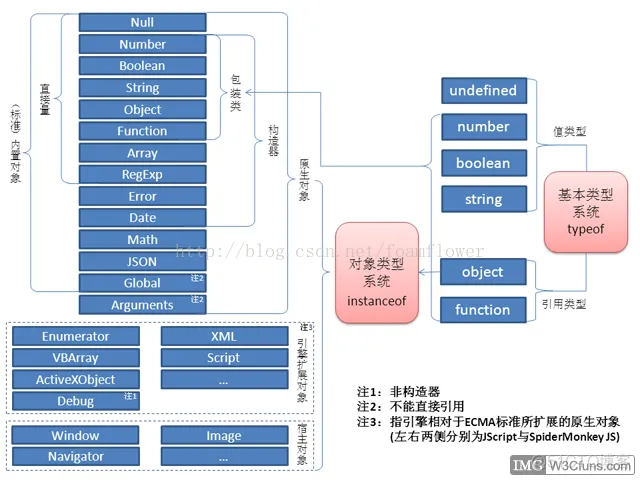
在JavaScript中,宿主对象(Host Objects)、内置对象(Built-in Objects)和原生对象(Native Objects)是与执行环境相关的概念。以下是它们的定义和区别:
宿主对象(Host Objects)
宿主对象是由JavaScript运行环境(如浏览器或Node.js)提供的,而不是由ECMAScript规范定义的对象。宿主对象的具体特性和行为可能会因不同的宿主环境而异。
-
定义:宿主对象是依赖于宿主环境(如浏览器或服务器)的对象,它们提供了与宿主环境交互的能力。
-
例子:
-
在浏览器中,
window、document、XMLHttpRequest等都是宿主对象。 -
在Node.js中,
global、process、console等都是宿主对象。
内置对象(Built-in Objects)
内置对象是由ECMAScript规范定义的对象,它们在任何JavaScript环境中都是可用的。这些对象提供了核心功能,如数据类型、错误处理、数学计算等。
-
定义:内置对象是ECMAScript规范中定义的对象,它们是语言的一部分,不依赖于宿主环境。
-
例子:
-
Object、Array、String、Number、Boolean等是内置对象,用于表示基本数据结构。 -
Date、Math、JSON、Error等也是内置对象,提供了特定的功能。
原生对象(Native Objects)
原生对象通常是指那些直接由JavaScript引擎实现的对象,包括内置对象和宿主对象。在某些文献中,"原生对象"这个术语可能与"内置对象"互换使用,但在严格意义上,原生对象包括了所有由JavaScript引擎直接实现的对象,无论是由ECMAScript规范定义的还是由宿主环境提供的。
-
定义:原生对象是由JavaScript引擎实现的对象,包括ECMAScript规范定义的对象和宿主环境提供的对象。
-
例子:
-
同内置对象和宿主对象的例子。
总结
-
宿主对象:依赖于宿主环境的对象,它们提供了与宿主环境交互的能力。
-
内置对象:由ECMAScript规范定义的对象,是JavaScript语言的核心组成部分。
-
原生对象:由JavaScript引擎实现的对象,包括内置对象和宿主对象。
在实际开发中,了解这些对象的来源和特性有助于更好地理解和使用JavaScript的各种功能。
=== 和==的区别?
在JavaScript中,=== 和 == 是用于比较两个值的运算符,但它们在比较时的行为和规则有所不同。
严格相等运算符 (===)
-
类型和值都相等:
===运算符称为严格相等运算符,它不仅比较两个值的类型,还比较它们的值。如果两个值的类型不同,即使它们的值看起来相同,===也会返回false。 -
不进行类型转换:使用
===时,如果比较的两个值类型不同,不会尝试进行任何类型转换,直接返回false。 -
例子:
3 === 3 // true
'3' === 3 // false,因为一个是字符串,一个是数字
相等运算符 (==)
-
只比较值:
==运算符称为相等运算符,它只比较两个值的值,而不关心它们的类型。如果两个值的类型不同,JavaScript 会尝试进行类型转换,使它们具有相同的类型,然后再进行比较。 -
进行类型转换:如果比较的两个值类型不同,
==会根据隐式类型转换规则尝试将它们转换为相同类型,然后再进行比较。 -
例子:
3 == 3 // true
'3' == 3 // true,因为字符串 '3' 被转换为数字 3 后比较
0 == false // true,因为 false 被转换为数字 0 后比较
'' == 0 // true,因为空字符串被转换为数字 0 后比较
推荐使用
通常推荐使用 === 运算符,因为它不会进行隐式的类型转换,这样可以避免很多由于类型转换导致的意外结果,使代码更加清晰和可靠。只有在你明确需要进行类型转换时,才使用 == 运算符。
例子
// 使用 ===
null === undefined // false,因为 null 和 undefined 是不同的类型
'0' === 0 // false,因为一个是字符串,一个是数字
// 使用 ==
null == undefined // true,JavaScript 会将 null 和 undefined 视为相等
'0' == 0 // true,因为字符串 '0' 被转换为数字 0
在实际开发中,使用 === 可以减少很多由于类型转换导致的bug,使得比较操作更加安全和可预测。
null,undefined的区别
-
null* 针对 对象 表示空对象
-
undefined* 针对 已经声明但是没有赋值 的 一个具体值
-
如果函数没有返回值,它会默认返回
undefined。 -
如果函数需要返回一个空对象,通常会返回
null。
拓展
在JavaScript中,null 和 undefined 是两种表示“没有值”的特殊值,它们用于不同的场景和目的。
null
-
定义:
null是一个表示故意赋予的空值的对象,它表示一个变量指向一个空对象。 -
用途:
-
表示一个变量初始化为空,即还没有指向任何对象。
-
表示函数期望返回一个对象,但没有找到合适的返回对象时,返回
null。 -
显式地表示一个空或不存在的对象引用。
-
类型:
null是Object类型(尽管在逻辑上它表示空,但技术上它是一个对象)。
undefined
-
定义:
undefined是一个表示变量已声明但尚未赋值的特殊值。 -
用途:
-
表示变量初始化未完成,即变量存在但还没有被赋予具体的值。
-
表示函数没有返回值时,默认返回
undefined。 -
表示对象中不存在某个属性。
-
类型:
undefined是Undefined类型。
区别
- 值的来源:
-
null是显式赋值的结果。 -
undefined是变量声明后未初始化的结果。
- 类型:
-
typeof null返回"object"(这是一个历史遗留问题,被认为是JavaScript的一个bug)。 -
typeof undefined返回"undefined"。
- 用途:
-
null通常用于表示空或无效的对象引用。 -
undefined通常用于表示未初始化或不存在的变量。
- 在函数中:
-
如果函数没有返回值,它会默认返回
undefined。 -
如果函数需要返回一个空对象,通常会返回
null。
例子
let a; // a 为 undefined,因为变量已声明但未初始化
let b = null; // b 为 null,因为显式地赋予了空值
function test() {
return; // 隐式返回 undefined
}
console.log(test()); // 输出 undefined
function test2() {
return null; // 显式返回 null
}
console.log(test2()); // 输出 null
在实际开发中,选择使用 null 还是 undefined 取决于你的具体需求和代码的上下文。通常,如果你需要表示一个变量指向一个空对象,使用 null;如果你需要表示一个变量尚未被初始化,使用 undefined。
怎么获取当前日期(年-月-日时:分:秒)?
new Date()
toLocaleString()
replace(///g, '-')
您的代码中有几个语法错误,我将帮您纠正这些错误,并提供一个正确的示例。您的目标似乎是创建一个日期对象,将其转换为本地字符串表示,然后替换斜杠(/)为破折号(-)。
以下是修正后的代码:
// 创建一个新的Date对象,它将包含当前的日期和时间
const a = new Date();
// 将日期转换为本地字符串格式
let b = a.toLocaleString();
// 替换字符串中的斜杠(/)为破折号(-)
b = b.replace(/\//g, '-');
console.log(b); // 输出格式化后的日期和时间
在这段代码中,new Date() 用于创建一个新的日期对象,toLocaleString() 方法用于将日期对象转换为易读的字符串格式。replace() 方法结合正则表达式 /\//g 用于全局替换字符串中的所有斜杠(/)为破折号(-)。
请注意,正则表达式中的双斜杠 // 是必要的,因为在字符串中单个斜杠是特殊字符的开始,我们需要对它进行转义。g 标志表示全局搜索,即替换所有出现的斜杠,而不仅仅是第一个。
如果您希望日期和时间的格式完全按照您的要求(例如,“年-月-日 时:分:秒”),您可能需要使用 toLocaleDateString() 和 toLocaleTimeString() 方法分别格式化日期和时间,然后组合它们,或者使用 options 参数自定义 toLocaleString() 的输出格式。
类数组,数组,对象,之间的 关系和互相转换方法
在JavaScript中,类数组(伪数组)、数组和对象是三种常用的数据结构,它们之间有着不同的特点和用途,但可以通过一些方法相互转换。
类数组(伪数组)与数组
类数组对象不是数组实例,但具有类似数组的特征,如具有索引和length属性。常见的类数组对象包括函数的arguments对象和某些DOM集合。
类数组转数组
- 使用
Array.from()方法:
let args = (function() {
return arguments; // 类数组对象
})(1, 2, 3);
let arr = Array.from(args); // [1, 2, 3]
- 使用扩展运算符(
...):
let args = (function() {
return arguments; // 类数组对象
})(1, 2, 3);
let arr = [...args]; // [1, 2, 3]
- 使用
Array.prototype.slice().call(args)方法:
let args = (function() {
return arguments; // 类数组对象
})(1, 2, 3);
let arr = Array.prototype.slice.call(args); // [1, 2, 3]
数组转类数组
数组本身就是类数组,但如果你想要创建一个真正的类数组对象(如arguments),可以使用Array对象并设置length属性。
数组与对象
数组是有序的数据集合,对象是键值对的集合。
数组转对象
- 使用
Array.prototype.reduce()方法:
let arr = ['a', 'b', 'c'];
let obj = arr.reduce((acc, val, index) => {
acc[val] = index + 1;
return acc;
}, {});
// { a: 1, b: 2, c: 3 }
- 使用对象字面量和数组索引:
let arr = ['a', 'b', 'c'];
let obj = {
a: arr[0],
b: arr[1],
c: arr[2]
};
// { a: 'a', b: 'b', c: 'c' }
对象转数组
- 使用
Object.keys()、Object.values()或Object.entries()方法:
let obj = { a: 1, b: 2, c: 3 };
let keys = Object.keys(obj); // ["a", "b", "c"]
let values = Object.values(obj); // [1, 2, 3]
let entries = Object.entries(obj); // [["a", 1], ["b", 2], ["c", 3]]
- 使用
Array.from()方法:
let obj = { a: 1, b: 2, c: 3 };
let values = Array.from(obj.values()); // [1, 2, 3]
- 使用
JSON.stringify()和JSON.parse()方法(对于简单对象):
let obj = { a: 1, b: 2, c: 3 };
let arr = JSON.parse(JSON.stringify(obj)); // ["a", 1, "b", 2, "c", 3]
请注意,JSON.stringify()和JSON.parse()方法在处理对象时会将对象转换为JSON字符串,然后再解析为数组,但这种方法会将键值对转换为连续的元素,而不是键值对的形式。
通过这些方法,你可以在类数组、数组和对象之间进行灵活的转换,以适应不同的编程场景和需求。
变量提升是什么?与函数提升的区别?
在JavaScript中,变量提升(Variable Hoisting)和函数提升(Function Hoisting)是两种不同的行为,它们都与JavaScript的执行上下文和作用域链有关。
变量提升
变量提升是指JavaScript引擎在代码执行之前,将变量声明提升到当前作用域的顶部。这意味着变量可以在声明之前就被访问。
console.log(myVar); // 输出 undefined
var myVar = 5;
在上面的代码中,尽管myVar是在console.log之后声明的,但是由于变量提升,myVar的声明被提升到了作用域顶部,所以在console.log执行时,myVar已经存在,其值为undefined。
对于let和const声明的变量,虽然也存在提升,但是它们不会立即被初始化,而是处于一个称为“暂时性死区”(Temporal Dead Zone, TDZ)的状态,直到它们被实际声明。
console.log(myLet); // 报错 ReferenceError
let myLet = 10;
函数提升
函数提升与变量提升类似,但是只适用于函数声明,不适用于函数表达式。在函数提升中,函数声明会被提升到当前作用域的顶部。
console.log(myFunc); // 报错 TypeError
myFunc(); // 输出 "Hello, World!"
function myFunc() {
console.log("Hello, World!");
}
在上面的代码中,尽管myFunc是在console.log之后声明的,但是由于函数提升,myFunc的声明被提升到了作用域顶部,所以在console.log执行时,myFunc已经存在,但是尝试打印一个函数会抛出错误。
区别
-
变量提升:适用于所有类型的变量声明(
var、let、const),但是let和const声明的变量在初始化之前不能被访问(TDZ)。 -
函数提升:只适用于函数声明,不适用于函数表达式。函数表达式不会提升,但是变量名会被提升。
函数表达式与函数声明的区别
-
函数声明:使用
function关键字,并且函数名是必需的。 -
函数表达式:通常是一个匿名函数,赋值给一个变量。
console.log(myFuncExpr); // 输出 undefined
myFuncExpr(); // 报错 TypeError
var myFuncExpr = function() {
console.log("Hello, World!");
};
在上面的代码中,myFuncExpr是一个函数表达式,它不会像函数声明那样被提升,所以console.log输出undefined,而myFuncExpr()在执行时抛出错误,因为此时myFuncExpr还没有被赋值。
总结来说,变量提升和函数提升是JavaScript在代码执行前对变量和函数声明进行处理的行为,它们对于理解JavaScript的作用域和执行上下文非常重要。
什么是作用域链?如何延长?
在jS解释器中查找一个变量或者函数时会首先从当前上下文对象中查找,如果当前上下文对象中不存在,就会向上层上下文中查找,直到找到该变量或者全局上下文时为止。这个查找过程中又上下文对象组成的链表结构就是作用域链。
通过闭包可以延长作用域链
如何实现数组的随机排序?
洗牌算法
在JavaScript中,实现数组的随机排序通常使用Fisher-Yates(也称为Knuth)洗牌算法。这个算法可以确保每个元素都有相同的概率出现在数组的任何位置。
以下是使用Fisher-Yates算法实现数组随机排序的步骤:
-
从数组的最后一个元素开始,随机选择一个元素与当前位置的元素交换。
-
移动到前一个元素,重复步骤1,直到遍历完整个数组。
下面是具体的实现代码:
function shuffleArray(array) {
let currentIndex = array.length,
temporaryValue,
randomIndex;
// 当仍有元素未洗牌时
while (currentIndex !== 0) {
// 选取一个剩余元素…
randomIndex = Math.floor(Math.random() * currentIndex);
currentIndex -= 1;
// 与当前元素交换
temporaryValue = array[currentIndex];
array[currentIndex] = array[randomIndex];
array[randomIndex] = temporaryValue;
}
return array;
}
// 示例
const myArray = [1, 2, 3, 4, 5];
console.log(shuffleArray(myArray));
在这个函数中,currentIndex 初始化为数组的长度,然后在每次迭代中减少。randomIndex 是从0到currentIndex(包括currentIndex)的随机索引。然后,将currentIndex指向的元素与randomIndex指向的元素交换。
这种方法确保每个元素都有相同的概率出现在数组的任何位置,从而实现了真正的随机排序。
请注意,这个函数会直接修改传入的数组。如果你需要保留原始数组,可以先复制一份数组再进行排序:
const originalArray = [1, 2, 3, 4, 5];
const arrayCopy = [...originalArray];
console.log(shuffleArray(arrayCopy));
console.log(originalArray); // 原始数组保持不变
使用扩展运算符(...)可以轻松地复制数组。
dom节点的Attribute和Property有何区别?
- attribute是HTML元素在标记中定义的属性,
而property是DOM元素在JavaScript中的属性。
- attribute表示初始HTML属性的值,无法反映元素当前的状态,
而property可以反映元素的实际状态。
- 通过getAttribute()和setAttribute()方法可以操作attribute,
通过直接访问DOM元素对象的属性来操作property.
拓展
在Web开发中,DOM(文档对象模型)节点的属性(Attribute)和特性(Property)是两个相关但不同的概念。它们在JavaScript中的表现和用途有所区别:
Attribute
-
定义:Attribute是定义在HTML标签内的,用于为HTML元素提供额外信息的键值对。
-
存储位置:Attribute存储在DOM中,可以通过
element.getAttribute()方法访问,也可以通过element.setAttribute()方法设置。 -
表现:Attribute通常在HTML标签中可见,例如
<input type="text" value="Hello">中的type和value。 -
编码:Attribute在HTML中是作为字符串存储的,即使它们看起来像数字或其他类型。
-
标准化:浏览器会根据HTML规范对Attribute进行标准化处理。
Property
-
定义:Property是JavaScript中DOM元素对象的属性,它们是可以通过JavaScript访问和修改的。
-
存储位置:Property是对象的属性,可以通过点符号(
.)或方括号([])访问和设置,例如element.property或element['property']。 -
表现:Property反映了元素的实时状态,它们可能与Attribute相对应,也可能不对应。
-
类型:Property是JavaScript变量,因此它们具有明确的类型,例如字符串、数字或布尔值。
-
更新:修改Property可能会影响元素的表现,但不一定影响HTML标签内的Attribute。
区别
-
来源:Attribute来自HTML标签,而Property来自DOM元素对象。
-
访问方式:Attribute通过
getAttribute和setAttribute方法访问,Property通过点符号或方括号访问。 -
同步性:对于布尔类型的Attribute和Property,它们通常是同步的,即修改一个另一个也会变。但对于其他类型,如
value属性,它们可能不同步,因为Property可能会被JavaScript代码修改,而Attribute只在HTML中更改。 -
类型转换:Attribute在HTML中总是字符串,而Property具有JavaScript的类型转换特性。
示例
考虑以下HTML元素:
<input type="text" value="Hello">
-
Attribute:
-
type="text":表示输入字段的类型。 -
value="Hello":表示输入字段的初始值。 -
Property:
-
input.type:在JavaScript中访问时,type是一个Property,其值为字符串"text"。 -
input.value:在JavaScript中访问时,value是一个Property,其值为字符串"Hello"。如果通过JavaScript更改input.value,输入字段的值会实时更新,但HTML标签中的valueAttribute不会改变。
在实际开发中,了解Attribute和Property之间的区别对于正确操作DOM元素非常重要。
dom结构操作怎样添加、移除、移动、复制、创建和查找节点?
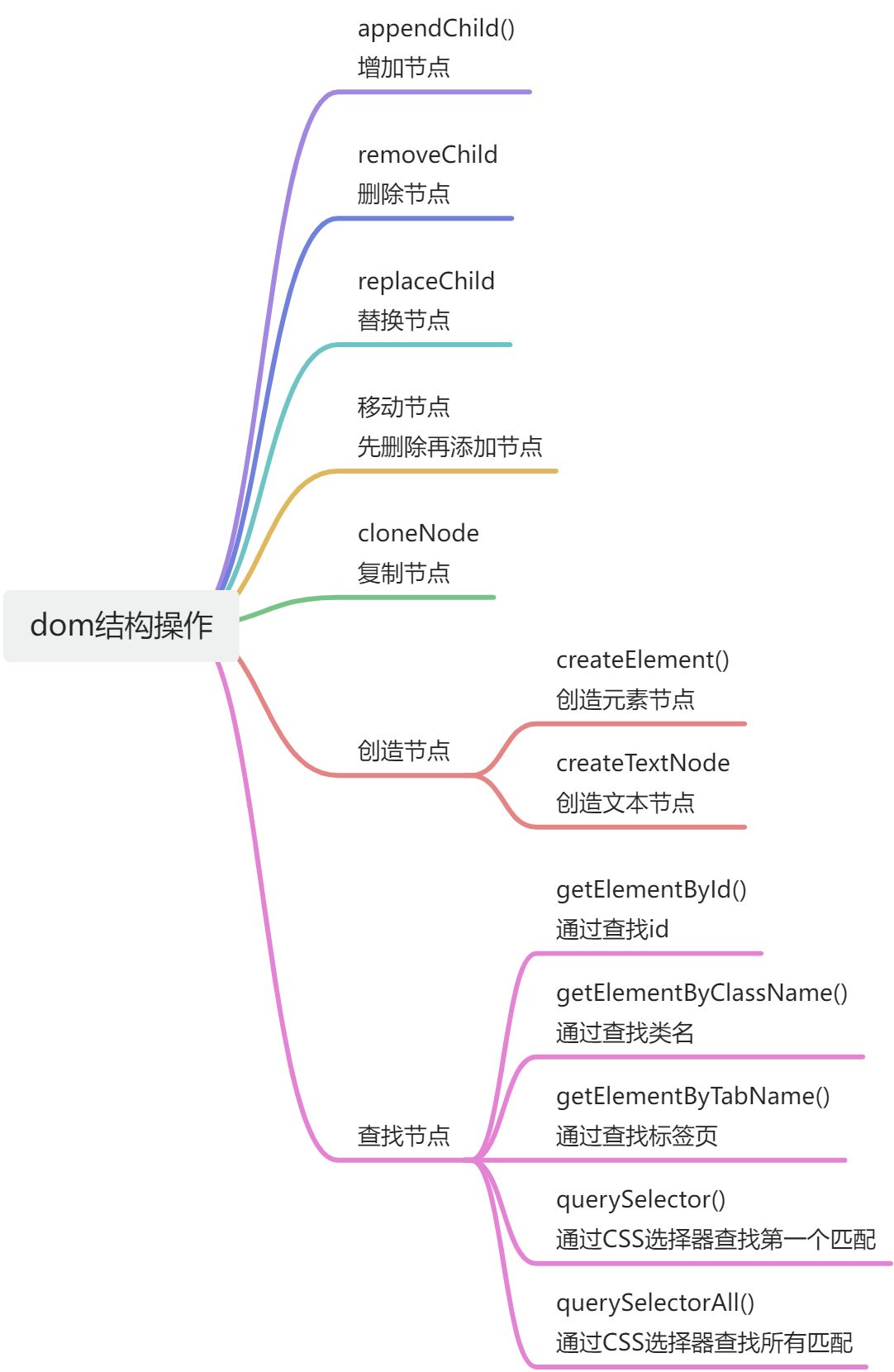
拓展
在JavaScript中,操作DOM(文档对象模型)结构是常见的任务,包括添加、移除、移动、复制、创建和查找节点。以下是这些操作的基本方法:
添加节点
使用appendChild()方法将新节点添加到父节点中。
var newElement = document.createElement('div');
var parentElement = document.getElementById('parent');
parentElement.appendChild(newElement);
移除节点
使用removeChild()方法从DOM中移除节点。
var elementToRemove = document.getElementById('removeMe');
var parentElement = elementToRemove.parentNode;
parentElement.removeChild(elementToRemove);
移动节点
移动节点通常是通过先移除再添加的方式实现。
var elementToMove = document.getElementById('moveMe');
var newParent = document.getElementById('newParent');
newParent.appendChild(elementToMove); // 相当于移动了节点
替换节点
使用replaceChild()方法替换一个节点。
var newElement = document.createElement('div');
var oldElement = document.getElementById('replaceMe');
var parentElement = oldElement.parentNode;
parentElement.replaceChild(newElement, oldElement);
复制节点
使用cloneNode()方法复制节点。注意,如果设置为true,它将复制节点及其所有子节点。
var elementToCopy = document.getElementById('copyMe');
var copiedElement = elementToCopy.cloneNode(false); // 只复制节点,不复制子节点
var parentElement = document.getElementById('parent');
parentElement.appendChild(copiedElement);
创建节点
使用createElement()方法创建新的元素节点。
var newElement = document.createElement('p');
使用createTextNode()方法创建新的文本节点。
var newText = document.createTextNode('这是一些文本');
查找节点
使用getElementById()方法通过ID查找节点。
var element = document.getElementById('myId');
使用getElementsByClassName()方法通过类名查找节点列表。
var elements = document.getElementsByClassName('myClass');
使用getElementsByTagName()方法通过标签名查找节点列表。
var elements = document.getElementsByTagName('div');
使用querySelector()方法通过CSS选择器查找第一个匹配的节点。
var element = document.querySelector('.myClass');
使用querySelectorAll()方法通过CSS选择器查找所有匹配的节点列表。
var elements = document.querySelectorAll('.myClass');
这些是操作DOM结构的基本方法。在实际应用中,你可能需要根据具体情况选择合适的方法来操作DOM。
什么是事件冒泡,它是如何工作的?如何阻止事件冒泡?
事件向上传播到根节点
event.stopPropagation() 阻止冒泡
拓展
事件冒泡(Event Bubbling)
事件冒泡是DOM事件传播的一种机制。当一个事件发生在某个元素上时,这个事件会从这个元素开始,逐级向上传播到根节点(document对象)。在这个过程中,每个父节点都会接收到这个事件,从而有机会对它进行处理。
工作原理
-
事件首先在触发它的元素(目标元素)上被处理。
-
然后,事件会逐级向上传播到父元素,直到达到根节点(
document对象)。 -
在这个过程中,任何父元素都有机会捕获并处理这个事件。
示例
假设你有以下的HTML结构:
<div id="parent">
<button id="child">点击我</button>
</div>
并且你有以下的JavaScript代码:
const childButton = document.getElementById('child');
const parentDiv = document.getElementById('parent');
childButton.addEventListener('click', function(event) {
console.log('按钮被点击');
});
parentDiv.addEventListener('click', function(event) {
console.log('容器被点击');
});
// 当你点击按钮时,会按照以下顺序触发事件:
// 1. 按钮被点击
// 2. 容器被点击
在这个例子中,当你点击按钮时,首先会触发按钮上的点击事件,然后事件会冒泡到父容器div上,触发父容器的点击事件。
如何阻止事件冒泡
虽然事件冒泡提供了一种强大的事件处理机制,但在某些情况下,你可能不希望事件继续向上传播。为了阻止事件冒泡,你可以使用event.stopPropagation()方法。
示例
继续使用上面的HTML结构,如果你只想处理按钮的点击事件,而不希望触发父容器的点击事件,你可以在按钮的点击事件处理函数中调用event.stopPropagation():
childButton.addEventListener('click', function(event) {
console.log('按钮被点击');
event.stopPropagation(); // 阻止事件冒泡
});
parentDiv.addEventListener('click', function(event) {
console.log('容器被点击');
});
在这个例子中,当你点击按钮时,只会触发按钮上的点击事件,而不会触发父容器的点击事件,因为event.stopPropagation()阻止了事件的进一步传播。
总结
事件冒泡是DOM事件处理中的一个重要概念,它允许事件在DOM树中向上传播。通过理解事件冒泡的工作原理,你可以更有效地控制事件处理逻辑。当需要阻止事件冒泡时,可以使用event.stopPropagation()方法来实现。
什么是事件捕获,它是如何工作的?
由外到内执行,捕获时间需要在监听时候添加第三个参数,为true
const parentDiv = document.getElementById('parent');
const childButton = document.getElementById('child');
// 在捕获阶段添加事件处理器
parentDiv.addEventListener('click', function(event) {
console.log('容器捕获点击');
}, true);
// 在冒泡阶段添加事件处理器
childButton.addEventListener('click', function(event) {
console.log('按钮被点击');
});
// 当你点击按钮时,会按照以下顺序触发事件:
// 1. 容器捕获点击
// 2. 按钮被点击
拓展
事件捕获(Event Capturing)是DOM事件传播的另一个阶段,与事件冒泡相对。在事件捕获阶段,事件从根节点(document对象)开始,沿着DOM树向下传播到目标元素。这意味着在事件到达目标元素之前,它首先会经过一系列的父元素和祖先元素。
工作原理
-
事件开始于根节点(document对象)。
-
事件沿着DOM树向下传播,直到到达目标元素。
-
在这个过程中,每个父元素都有机会捕获并处理事件,这发生在事件到达目标元素之前。
事件传播的三个阶段
-
事件捕获阶段:事件从document对象开始,向下传播到目标元素的任何父元素或祖先元素。
-
目标阶段:事件到达目标元素。
-
事件冒泡阶段:事件从目标元素向上传播回document对象。
如何使用事件捕获
在JavaScript中,你可以通过在addEventListener方法中设置第三个参数来指定事件处理器是在捕获阶段还是冒泡阶段被触发。如果你想在捕获阶段触发事件处理器,可以将第三个参数设置为true。
示例
const parentDiv = document.getElementById('parent');
const childButton = document.getElementById('child');
// 在捕获阶段添加事件处理器
parentDiv.addEventListener('click', function(event) {
console.log('容器捕获点击');
}, true);
// 在冒泡阶段添加事件处理器
childButton.addEventListener('click', function(event) {
console.log('按钮被点击');
});
// 当你点击按钮时,会按照以下顺序触发事件:
// 1. 容器捕获点击
// 2. 按钮被点击
在这个例子中,点击按钮会首先触发父容器的点击事件(在捕获阶段),然后才是按钮本身的点击事件(在冒泡阶段)。
如何阻止事件捕获
如果你想阻止事件在捕获阶段继续传播,可以使用event.stopPropagation()方法。这将阻止事件进一步向下传播到目标元素或任何子元素。
parentDiv.addEventListener('click', function(event) {
console.log('容器捕获点击');
event.stopPropagation(); // 阻止事件进一步传播
}, true);
childButton.addEventListener('click', function(event) {
console.log('按钮被点击');
}, true);
在这个例子中,由于在父容器的事件处理器中调用了event.stopPropagation(),点击按钮将不会触发按钮本身的点击事件。
总结
事件捕获提供了一种在事件到达目标元素之前处理事件的机制。通过在addEventListener中设置true作为第三个参数,你可以在捕获阶段注册事件处理器。这允许你在事件到达目标元素之前进行干预,例如在父元素中捕获事件并阻止它进一步传播。
dom的事件模型
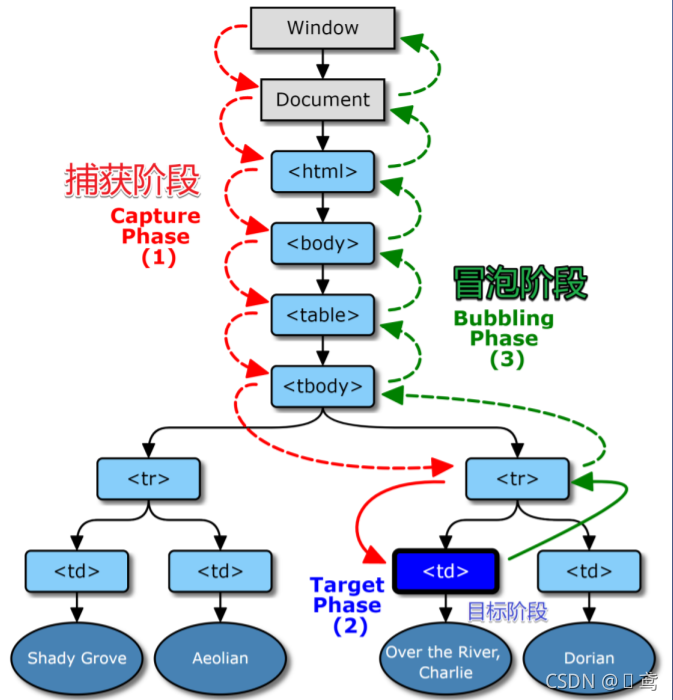
DOM 事件模型
-
addEventListener:绑定事件的监听函数 -
removeEventListener:移除事件的监听函数 -
dispatchEvent:触发事件
事件模型
-
由外向内找监听函数就是事件捕获
-
在目标节点触发事件
-
由内而外找监听函数就是事件冒泡
事件传播的最上层对象是window,上例的事件传播顺序,
在捕获阶段依次为window、document、html、body、父节点、目标节点,
在冒泡阶段依次为目标节点、父节点、body、html、document、window。
DOM事件传播的三个阶段:捕获阶段,目标阶段,冒泡阶段
- target v.s. currentTarget的区别*
区别
e.target - 用户操作的元素
e.currentTarget-程序员监听的元素
this是e.currentTarget,我个人不推荐使用它
举例:
div>span{文字},用户点击文字
e.target就是span
e.currentTarget就是div

- e.stopPropagation():取消冒泡*
e.stopPropagation()可打断冒泡,浏览器不再向上走
一般用于封装某些独立组件
事件委托
事件委托的优点包括:
-
减少内存消耗:因为只需要在父元素上设置一个事件处理程序,而不是在每个子元素上都设置。
-
动态元素管理:对于动态添加到DOM中的元素,不需要单独为它们添加事件处理程序,因为它们会继承父元素的事件处理程序。
-
简化代码:可以简化事件处理代码,特别是当有多个元素需要相同类型的事件处理时。
事件委托的实现示例:
html
<div id="parent">
<button>按钮1</button>
<button>按钮2</button>
<!-- 更多按钮 -->
</div>
javascript复制
const parentDiv = document.getElementById('parent');
parentDiv.addEventListener('click', function(event) {
const target = event.target; // 事件实际触发的元素
if (target.tagName === 'BUTTON') {
console.log('按钮被点击', target.textContent);
}
});
拓展
DOM(文档对象模型)的事件模型描述了如何在用户与页面交互时处理事件。在Web开发中,主要有两种事件模型:DOM Level 0事件模型和DOM Level 2事件模型。
DOM Level 2事件模型
这是现代浏览器使用的事件模型,它提供了更灵活和强大的事件处理机制。在DOM Level 2事件模型中:
- 事件监听:事件处理程序通过JavaScript的
addEventListener方法添加到元素上,可以动态添加和移除。
element.addEventListener('click', function(event) {
// 处理事件
}, false);
- 事件对象:当事件被触发时,会创建一个事件对象,它包含了事件的所有信息,如事件类型、目标、时间戳等。这个对象作为参数传递给事件处理函数。
function handleClick(event) {
console.log(event.type); // "click"
console.log(event.target); // 事件目标元素
}
- 事件传播:事件在DOM中传播的过程包括三个阶段:
-
捕获阶段(Capturing Phase):事件从根节点(document对象)开始,向下传播到目标元素。
-
目标阶段(Target Phase):事件到达目标元素。
-
冒泡阶段(Bubbling Phase):事件从目标元素向上传播回根节点。
-
事件流:可以通过设置
addEventListener的第三个参数来控制事件处理是在捕获阶段还是冒泡阶段触发。默认情况下(第三个参数为false),事件处理在冒泡阶段触发。如果设置为true,则在捕获阶段触发。 -
事件取消:可以使用
event.preventDefault()方法取消事件的默认行为,使用event.stopPropagation()方法阻止事件进一步传播。 -
事件委托:由于事件冒泡的特性,可以在父元素上设置一个事件处理程序来管理所有子元素的同一类事件,这称为事件委托。这有助于减少内存消耗并简化代码。
现代Web开发中,推荐使用DOM Level 2事件模型,因为它提供了更好的控制和更丰富的特性集。
事件对象
在DOM事件处理中,当一个事件发生时,浏览器会创建一个事件对象(通常表示为event),这个对象包含了关于事件的详细信息,以及一些可以调用的方法。事件对象作为参数自动传递给事件处理函数。
事件对象包含以下常见的属性和方法:
-
type:事件的类型,例如"click"、"mouseover"等。 -
target:触发事件的元素,也就是事件绑定的元素。 -
currentTarget:事件处理程序当前正在被执行的元素,这在事件委托中特别有用。 -
eventPhase:当前事件处于的阶段(捕获阶段、目标阶段或冒泡阶段)。 -
bubbles:指示事件是否冒泡。 -
cancelable:指示事件是否可以被取消。 -
timeStamp:事件被创建时的时间戳。 -
preventDefault():取消事件的默认行为。 -
stopPropagation():停止事件进一步传播。 -
stopImmediatePropagation():停止事件的进一步传播,并且阻止同一元素上其他同类型事件的执行。
事件委托
事件委托是一种技术,它利用了事件冒泡的原理。在这种技术中,事件监听器不是直接绑定在目标元素上,而是绑定在目标元素的父元素或祖先元素上。当子元素(目标元素)触发事件时,这个事件会冒泡到父元素,父元素上的事件处理程序就会执行。
事件委托的优点包括:
-
减少内存消耗:因为只需要在父元素上设置一个事件处理程序,而不是在每个子元素上都设置。
-
动态元素管理:对于动态添加到DOM中的元素,不需要单独为它们添加事件处理程序,因为它们会继承父元素的事件处理程序。
-
简化代码:可以简化事件处理代码,特别是当有多个元素需要相同类型的事件处理时。
事件委托的实现示例:
<div id="parent">
<button>按钮1</button>
<button>按钮2</button>
<!-- 更多按钮 -->
</div>
const parentDiv = document.getElementById('parent');
parentDiv.addEventListener('click', function(event) {
const target = event.target; // 事件实际触发的元素
if (target.tagName === 'BUTTON') {
console.log('按钮被点击', target.textContent);
}
});
在这个例子中,我们只在父元素div上设置了一个点击事件的监听器。当任何按钮被点击时,事件会冒泡到div,然后事件处理程序会检查事件的目标是否是按钮。如果是,就执行相应的操作。这样,即使后续添加了更多的按钮,也不需要为它们单独设置事件监听器。
事件三要素是什么?
-
事件类型(Event Type)*
-
事件目标(Event Target)*
-
事件处理器(Event Handler)*
拓展
在DOM(文档对象模型)事件处理中,通常提到事件的三个基本要素,它们是:
- 事件类型(Event Type):
- 这是触发事件的具体动作,比如
click、mouseover、keydown等。事件类型告诉你发生了什么类型的交互或动作。
- 事件目标(Event Target):
- 这是触发事件的DOM元素。例如,如果你点击了一个按钮,那么这个按钮元素就是事件的目标。
- 事件处理器(Event Handler):
- 这是当事件发生时,要执行的函数或代码。事件处理器是你定义的逻辑,用于响应特定的事件。
事件对象(Event Object)
除了上述三个要素,还有一个重要的组成部分是事件对象。当事件被触发时,浏览器会创建一个事件对象,该对象包含了事件的详细信息和一些方法,用于控制事件的传播和默认行为。
-
事件对象(Event Object):
-
这个对象作为参数自动传递给事件处理器函数。它提供了关于事件的详细信息,如事件的类型、目标、时间、是否可取消等。
-
事件对象的方法包括
preventDefault()(取消事件的默认行为)、stopPropagation()(停止事件的进一步传播)和stopImmediatePropagation()(停止事件的进一步传播,并阻止同一元素上其他同类型事件的执行)。
示例
// 获取一个DOM元素
const button = document.getElementById('myButton');
// 定义一个事件处理器函数
function handleClick(event) {
console.log('按钮被点击了');
console.log('事件类型:', event.type); // 事件类型
console.log('事件目标:', event.target); // 事件目标
// 可以调用事件对象的方法来控制事件行为
event.preventDefault();
event.stopPropagation();
}
// 为按钮添加点击事件监听器
button.addEventListener('click', handleClick);
在这个示例中,当按钮被点击时,会触发handleClick事件处理器。这个处理器接收一个事件对象作为参数,从中可以访问事件的类型和目标,并且可以使用事件对象的方法来控制事件的行为。
获取元素位置?
拓展
在JavaScript中,获取元素的位置可以通过几种不同的方法,这些方法可以帮助你确定元素在页面上的确切位置,包括它距离页面左上角的距离,或者相对于其父元素的位置。以下是一些常用的方法:
1. offsetLeft 和 offsetTop
这两个属性返回元素相对于其定位父元素(offset parent)的左(left)和顶(top)边的距离。
const element = document.getElementById('myElement');
const xPos = element.offsetLeft;
const yPos = element.offsetTop;
2. getBoundingClientRect()
这个方法返回元素的大小以及其相对于视口的位置。它返回的是一个矩形对象,包含top、right、bottom、left、width和height属性。
const element = document.getElementById('myElement');
const rect = element.getBoundingClientRect();
const top = rect.top;
const right = rect.right;
const bottom = rect.bottom;
const left = rect.left;
const width = rect.width;
const height = rect.height;
3. offsetParent
这个属性返回最近的含有定位(positioned)的父元素。如果所有父元素都没有定位,则返回最近的<table>或<td>元素,如果这些元素也不存在,则返回<body>元素。
const element = document.getElementById('myElement');
const positionedParent = element.offsetParent;
4. clientLeft 和 clientTop
这两个属性返回元素的边框宽度(border width),可以用来确定元素的内部尺寸。
const element = document.getElementById('myElement');
const borderLeft = element.clientLeft;
const borderTop = element.clientTop;
5. scrollLeft 和 scrollTop
如果你需要获取元素的滚动位置,可以使用这两个属性。
const element = document.getElementById('myElement');
const scrollLeft = element.scrollLeft;
const scrollTop = element.scrollTop;
示例:获取元素相对于视口的位置
以下示例展示了如何获取元素相对于浏览器视口的位置:
const element = document.getElementById('myElement');
const rect = element.getBoundingClientRect();
const xPos = rect.left + window.scrollX; // 添加水平滚动距离
const yPos = rect.top + window.scrollY; // 添加垂直滚动距离
console.log(`Element is positioned at ${xPos} on the X-axis and ${yPos} on the Y-axis relative to the viewport.`);
这些方法可以帮助你确定元素在页面上的位置,无论是相对于其父元素还是相对于整个视口。这对于执行动态布局、拖放功能或任何需要精确位置信息的操作都非常有用。
setTimeout和setInterval的区别及用法是什么?
setTimeout(function, delay, [arg1, arg2, ...]);
setInterval(function, interval, [arg1, arg2, ...]);
clearTimeout(timeoutId); // 停止setTimeout
clearInterval(intervalId);
拓展
setTimeout和setInterval是JavaScript中用于定时执行代码的两个函数,它们都属于Window对象,也可用于Worker。尽管它们的目的相似,但用法和行为有所不同。
setTimeout
setTimeout用于在指定的毫秒数后执行一次代码。
用法:
setTimeout(function, delay, [arg1, arg2, ...]);
-
function: 要执行的函数。 -
delay: 延迟时间,单位为毫秒。 -
arg1, arg2, ...: 可选参数,传递给函数的参数。
示例:
function sayHello() {
console.log('Hello after 3 seconds');
}
setTimeout(sayHello, 3000); // 3秒后执行sayHello函数
setInterval
setInterval用于按照指定的时间间隔周期性地执行代码。
用法:
setInterval(function, interval, [arg1, arg2, ...]);
-
function: 要执行的函数。 -
interval: 每次执行的间隔时间,单位为毫秒。 -
arg1, arg2, ...: 可选参数,传递给函数的参数。
示例:
function repeatHello() {
console.log('Hello every 2 seconds');
}
const intervalId = setInterval(repeatHello, 2000); // 每2秒执行一次repeatHello函数
区别
-
执行次数:
setTimeout执行一次后停止,而setInterval会不断重复执行,直到你明确地停止它(使用clearInterval)。 -
延迟与间隔:
setTimeout的延迟是指从调用setTimeout到函数执行之间的时间。setInterval的间隔是指函数执行之间的时间。 -
停止执行:
setTimeout不需要手动停止,因为执行一次后自然结束。setInterval需要使用clearInterval来停止。
停止定时器
-
clearTimeout用于停止setTimeout。 -
clearInterval用于停止setInterval。
示例:
const timeoutId = setTimeout(function() {
console.log('This will not run');
}, 5000);
clearTimeout(timeoutId); // 停止setTimeout
const intervalId = setInterval(function() {
console.log('This will run until it is cleared');
}, 1000);
// 运行一段时间后停止
setTimeout(function() {
clearInterval(intervalId);
}, 10000);
注意事项
-
当使用
setInterval时,如果执行的函数耗时较长,可能会导致执行重叠,即上一次执行还没完成,下一次又开始了。为了避免这种情况,可以使用setTimeout递归调用自身。 -
setTimeout和setInterval的精确度受到JavaScript单线程模型的限制,如果主线程被其他任务阻塞,定时器可能会延迟执行。
setTimeout来实现setInterval
var timeWorker = {}
var mySetInterval= function(fn, time) {
// 定义一个key,来标识此定时器
var key = Symbol();
// 定义一个递归函数,持续调用定时器
var execute = function(fn, time) {
timeWorker[key] = setTimeout(function(){
fn();
execute(fn, time);
}, time)
}
execute(fn, time);
// 返回key
return key;
}
var myClearInterval = function(key) {
if (key in timeWorker) {
clearTimeout(timeWorker[key]);
delete timeWorker[key];
}
}
拓展这段代码定义了两个函数:mySetInterval 和 myClearInterval,它们模拟了 setInterval 和 clearInterval 的行为,但是使用了 setTimeout 来实现。这种方法可以避免 setInterval 可能带来的一些问题,比如函数执行时间的不确定性和最小时间间隔的限制。
mySetInterval 函数
这个函数接收两个参数:
-
fn:要重复执行的函数。 -
time:执行间隔时间,单位为毫秒。
函数内部:
-
定义了一个
key,使用Symbol来确保唯一性,这样可以在timeWorker对象中唯一标识每个定时器。 -
定义了一个
execute函数,它使用setTimeout来实现定时调用fn函数。每次fn执行后,execute函数会再次调用自己,形成一个递归循环。 -
调用
execute函数开始执行定时任务。 -
返回
key,这个key可以用于以后取消定时任务。
myClearInterval 函数
这个函数用于取消由 mySetInterval 设置的定时任务。
-
它接收一个
key参数,这个key是mySetInterval返回的。 -
如果
timeWorker对象中存在这个key,则使用clearTimeout来取消对应的定时器,然后从timeWorker对象中删除这个key。
使用示例
var myIntervalKey = mySetInterval(function() {
console.log('这条消息会每2秒打印一次');
}, 2000);
// 当你想停止定时任务时
myClearInterval(myIntervalKey);
注意事项
-
确保在不需要定时任务时调用
myClearInterval来清除定时器,避免内存泄漏。 -
由于使用了
Symbol作为key,所以每个定时器都是唯一的,即使在多个mySetInterval调用之间也不会冲突。 -
这种方法比直接使用
setInterval更灵活,因为它允许你在每次迭代后根据需要调整间隔时间或停止定时器。
document.write和innerHTML的区别?
document.write 主要用于在文档加载时写入内容,
而 innerHTML 用于在文档加载完成后修改元素的内容。
拓展
document.write 和 innerHTML 都是用来操作HTML文档内容的方法,但它们在用法和用途上有一些区别:
document.write
-
document.write是一个只读属性,它返回当前文档的内容,如果尝试读取它的值,会返回空字符串。 -
document.write方法可以用来向文档中写入字符串参数。当调用这个方法时,它会将字符串参数写入文档的输出流中。 -
document.write只能用于在加载文档的过程中写入内容,一旦文档加载完成(即DOMContentLoaded事件之后),再使用document.write会清空整个文档的内容。 -
document.write通常在服务器生成HTML或在文档加载时由JavaScript动态生成内容时使用。
innerHTML
-
innerHTML是一个属性,它返回指定元素内的HTML内容。 -
innerHTML可以用来读取或设置元素内的HTML内容。当你设置一个元素的innerHTML属性时,它会替换该元素内部的所有内容(包括子元素)。 -
innerHTML可以在任何时候使用,即使在文档加载完成后也可以安全地使用,不会导致整个文档内容被清空。 -
innerHTML常用于动态更新页面的部分内容,比如通过JavaScript操作DOM来更改或添加新的元素和文本。
区别
-
用途:
document.write主要用于在文档加载时写入内容,而innerHTML用于在文档加载完成后修改元素的内容。 -
安全性:
innerHTML可以导致跨站脚本(XSS)攻击,因为它允许执行HTML和JavaScript。在使用innerHTML时,需要确保内容是安全的,不包含用户输入的恶意代码。document.write也有类似的安全风险。 -
灵活性:
innerHTML更灵活,因为它可以用于单个元素,而document.write影响整个文档。 -
性能:频繁使用
innerHTML可能会导致性能问题,因为它涉及到DOM的重绘和重排。document.write在文档加载时使用,不涉及重绘和重排的问题。
示例
// 使用 document.write
document.write('<p>Hello World</p>');
// 使用 innerHTML
var element = document.getElementById('myElement');
element.innerHTML = '<strong>Bold Text</strong>';
在实际开发中,推荐使用 innerHTML 来动态更新页面内容,因为它提供了更好的控制和灵活性。同时,要注意防范XSS攻击,确保处理的内容是安全的。
元素拖动如何实现,原理是怎样?
原生
-
mousedown:当鼠标按下时,记录当前鼠标位置和元素的初始位置。
-
mousemove:当鼠标移动时,计算鼠标的新位置,并相应地移动元素。
-
mouseup:当鼠标释放时,停止移动元素。
使用HTML5拖放API
-
draggable属性:给元素添加
draggable="true"属性,使其可拖动。 -
拖动事件:监听
dragstart、dragover、dragend等事件来控制拖动过程。
拓展
元素拖动是Web开发中常见的交互功能,可以通过原生JavaScript或HTML5的拖放API来实现。以下是两种方法的实现方式和原理:
使用原生JavaScript
原生JavaScript实现元素拖动的原理是监听鼠标事件,通过计算鼠标移动的距离来更新元素的位置。
-
mousedown:当鼠标按下时,记录当前鼠标位置和元素的初始位置。
-
mousemove:当鼠标移动时,计算鼠标的新位置,并相应地移动元素。
-
mouseup:当鼠标释放时,停止移动元素。
示例代码
var dragElement = document.getElementById('draggable');
var offsetX, offsetY, dragX, dragY;
dragElement.onmousedown = function(e) {
// 获取鼠标点击时的屏幕坐标
offsetX = e.clientX - dragX;
offsetY = e.clientY - dragY;
// 绑定移动和松开事件
document.onmousemove = dragMove;
document.onmouseup = stopDragging;
};
function dragMove(e) {
// 计算元素新的位置
dragX = e.clientX - offsetX;
dragY = e.clientY - offsetY;
// 设置元素的新位置
dragElement.style.left = dragX + 'px';
dragElement.style.top = dragY + 'px';
}
function stopDragging() {
// 解除鼠标移动和松开事件
document.onmouseup = null;
document.onmousemove = null;
}
使用HTML5拖放API
HTML5提供了一套拖放API,可以更方便地实现拖动功能。
-
draggable属性:给元素添加
draggable="true"属性,使其可拖动。 -
拖动事件:监听
dragstart、dragover、dragend等事件来控制拖动过程。
示例代码
<div id="draggable" draggable="true">可拖动的元素</div>
<div id="dropzone">放置区域</div>
<script>
var dragItem = document.getElementById('draggable');
var dropZone = document.getElementById('dropzone');
dragItem.addEventListener('dragstart', function(e) {
// 拖动开始时的事件处理
});
dropZone.addEventListener('dragover', function(e) {
// 阻止默认行为以启用drop
e.preventDefault();
});
dropZone.addEventListener('drop', function(e) {
// 拖动结束并放置时的事件处理
var data = e.dataTransfer.getData("text");
// 将拖动的元素移动到放置区域
dropZone.appendChild(dragItem);
});
</script>
原理
-
鼠标事件:通过监听鼠标事件来控制元素的移动。
-
事件委托:在
document上监听事件,而不是直接在元素上,这样可以处理从元素外部移动到元素内部的情况。 -
坐标计算:计算鼠标移动的距离,并更新元素的位置。
-
CSS定位:通常使用CSS的
position属性(如absolute或fixed)来使元素脱离文档流,从而可以自由移动。
在实际应用中,可以根据具体需求选择使用原生JavaScript或HTML5拖放API来实现元素拖动。HTML5拖放API提供了更丰富的功能和更好的浏览器兼容性,但可能需要处理更多的事件和细节。原生JavaScript方法则更灵活,可以自定义更多的行为和样式。
图片懒加载和预加载实现
页面加载就像吃饭,懒加载就是吃多少盛多少,预加载就是把饭先盛好等你吃
懒加载和预加载实现
lazy preload https://blog.csdn.net/weixin_49078296/article/details/140249963
https://blog.csdn.net/qq_44741577/article/details/139324747
拓展
图片的懒加载(Lazy Loading)和预加载(Preloading)是两种优化网页性能的技术,它们分别用于减少初始页面加载时间并提高用户体验。
图片懒加载
懒加载是一种延迟加载网页中非关键资源的技术。对于图片而言,懒加载意味着图片只有在接近滚动到视窗(viewport)时才开始加载。
- 优点*:
-
减少初始页面加载时间:页面加载时不需要加载所有图片,从而减少了HTTP请求和数据传输量。
-
节省带宽:用户可能只浏览页面的一部分,懒加载可以确保未浏览到的图片不会被加载。
-
提高性能:对于图片较多的页面,懒加载可以显著提高页面的响应速度和性能。
- 实现方式*:
-
原生JavaScript:通过监听滚动事件和计算元素的位置来实现。
-
HTML5
loading属性:<img loading="lazy">,现代浏览器支持这个属性,可以自动实现图片懒加载。 -
Intersection Observer API:这是一个更现代和更高效的方法,用于异步检测目标元素与祖先元素或顶级文档视窗(
viewport)的交叉状态。
图片预加载
预加载是一种在页面加载时就提前加载资源的技术。对于图片而言,预加载意味着在用户浏览到图片之前,图片已经被加载到浏览器缓存中。
- 优点*:
-
提高用户体验:用户滚动到图片位置时,图片已经加载完成,无需等待加载。
-
减少加载时间:通过提前加载图片,可以减少用户实际看到图片时的加载时间。
- 实现方式*:
preload** 关键字**:在CSS中使用preload关键字预加载关键图片。
link rel="preload" href="image.jpg" as="image"
- JavaScript:使用JavaScript动态创建图片元素并设置其
src属性来预加载图片。
const preloadImage = (url) => {
const img = new Image();
img.src = url;
};
preloadImage('important-image.jpg');
- CSS Sprites:将多个小图标合并到一个图片文件中,然后通过CSS背景位置来显示不同的图标,这样可以减少HTTP请求。
选择懒加载还是预加载?
-
懒加载:适用于图片数量众多且不是所有图片都会立即需要的场景,特别是在长页面滚动或无限滚动的网页中。
-
预加载:适用于关键路径上的资源,比如首屏显示的图片或对用户体验至关重要的资源。
在实际应用中,可以根据页面的具体需求和用户行为来决定使用懒加载、预加载或两者结合使用。例如,对于首屏内容可以采用预加载,而对于页面下方的内容则可以使用懒加载。
mouseover和mouseenter的区别
mouseover:只要鼠标指计移入事件所绑定的元素或其子元素,都会触发该事件
mouseenter:只有鼠标指引事件所绑定的元素时,才会触发该事件
就是mouseover存在冒泡,mouseenter不存在
拓展
mouseover 和 mouseenter 都是鼠标事件,但它们在触发行为和事件传播上有所不同。
mouseover
-
当鼠标指针移动到元素上时触发。
-
如果鼠标指针移动到其子元素上,也会触发父元素上的
mouseover事件。 -
事件会冒泡,意味着如果鼠标指针移动到一个元素的子元素上,父元素也会接收到事件。
mouseenter
-
当鼠标指针移动到元素上时触发,与
mouseover类似。 -
不同之处在于,当鼠标指针移动到其子元素上时,不会再次触发父元素上的
mouseenter事件。 -
事件不会冒泡,父元素不会因子元素上的鼠标指针移动而触发
mouseenter事件。
区别总结
-
事件传播:
mouseover会冒泡,而mouseenter不会。 -
子元素交互:当鼠标指针移动到子元素上时,
mouseover会在所有包含的元素上触发,而mouseenter只在最初进入的元素上触发一次。
示例
<div id="parent" onmouseenter="console.log('parent mouseenter')">
<div id="child" onmouseenter="console.log('child mouseenter')">
Hover over me!
</div>
</div>
在这个例子中,当你将鼠标指针移动到子元素上时:
-
使用
mouseenter,只会打印 "parent mouseenter" 一次,即使鼠标指针在子元素上移动,也不会再次触发父元素上的mouseenter事件。 -
如果将
mouseenter改为mouseover,则每次鼠标指针移动到子元素的不同位置时,都会触发父元素上的mouseover事件,因为mouseover会冒泡。
选择使用 mouseover 还是 mouseenter 取决于你是否需要处理事件冒泡以及对子元素的交互是否敏感。
new操作符做了哪些事情
创建一个新对象
新对象原型指向构造函数原型对象
将 新对象的赋值 给 构造函数 this
根据返回值判断
拓展
这段代码是一个自定义的构造函数 mynew,它模拟了 JavaScript 中 new 操作符的行为。下面是对代码的逐行解释:
-
创建一个新对象
obj,这个对象将作为构造函数的实例。 -
将新对象的原型指向构造函数
Func的原型对象,这样新对象就可以继承构造函数的原型上的属性和方法。 -
使用
Func.apply(obj, args)调用构造函数,并将this指向新对象obj,同时传入构造函数所需的参数args。这里有一个语法错误,应该是Func.apply(obj, args)而不是let result Func.apply(obj,args)。 -
判断构造函数的返回值。如果返回值是一个对象,则返回该对象;否则,返回新创建的对象
obj。
修正后的代码如下:
function mynew(Func, ...args) {
// 1. 创建一个新对象
const obj = {};
// 2. 新对象原型指向构造函数原型对象
obj.__proto__ = Func.prototype;
// 3. 将构造函数的this指向新对象
const result = Func.apply(obj, args);
// 4. 根据返回值判断
return result instanceof Object ? result : obj;
}
这样,mynew 函数就可以像 new 操作符一样使用了。例如:
function Person(name) {
this.name = name;
}
Person.prototype.sayHello = function() {
console.log(`Hello, my name is ${this.name}.`);
};
const person = mynew(Person, 'Kimi');
person.sayHello(); // 输出: Hello, my name is Kimi.
请注意,虽然这个自定义的 mynew 函数可以模拟 new 操作符的行为,但在实际开发中,直接使用 new 操作符更为简洁和可靠。此外,现代 JavaScript 开发中更推荐使用 class 关键字来定义类和构造函数。
平时是怎么调试]S的
- 浏览器开发者工具*
console** API**
- 断点*
拓展
调试 JavaScript 代码是开发过程中的一个重要环节,可以帮助你理解代码的执行流程、查找和修复错误。以下是一些常用的 JavaScript 调试技巧和工具:
- 浏览器开发者工具:
-
Chrome DevTools: Chrome 浏览器内置的开发者工具非常强大,提供了元素检查、控制台、网络监控、性能分析、内存分析、断点调试等功能。
-
Firefox Developer Tools: Firefox 浏览器的开发者工具同样提供了类似的功能,包括但不限于元素检查器、控制台、调试器、网络监控等。
- 使用
consoleAPI:
-
console.log(): 输出信息到控制台,是最常用的调试方法。 -
console.error(): 输出错误信息,通常会显示在控制台的错误区域。 -
console.warn(): 输出警告信息,用于提示潜在的问题。 -
console.info(): 输出一般信息。 -
console.debug(): 输出调试信息,通常只在调试模式下显示。 -
console.table(): 以表格形式展示对象的属性。 -
console.group()和console.groupEnd(): 用于将相关的输出分组。
- 断点和步进执行:
-
在代码中你想要检查的地方设置断点。
-
使用步进(Step into)、步过(Step over)、步出(Step out)来逐行或逐函数执行代码。
- 使用
debugger语句:
- 在代码中添加
debugger语句,当执行到这一行时,如果开发者工具是打开状态,代码执行将暂停。
- 源代码映射(Source Maps):
- 当你使用构建工具(如 Webpack、Gulp 等)压缩或转译代码时,源代码映射可以帮助你将压缩后的代码映射回原始源代码,方便调试。
- 性能分析器:
- 使用浏览器的 Performance tab 来记录和分析页面加载和运行时的性能瓶颈。
- 内存分析:
- 使用 Heap Snapshot 和 Allocation Timeline 来分析内存使用情况,查找内存泄漏。
- 网络监控:
- 监控和分析页面的网络请求,包括请求的资源、加载时间、请求方法、状态码等。
- 使用调试器 API:
- 浏览器提供了一些调试相关的 API,如
console.clear()来清除控制台输出,console.count()来计数同一行代码被执行的次数等。
- 单元测试:
- 使用单元测试框架(如 Jest、Mocha、Jasmine)来编写测试用例,自动测试代码逻辑。
- 代码审查:
- 通过代码审查来发现潜在的问题,这可以是自我审查或者团队成员之间的相互审查。
- 使用第三方调试工具:
- 除了浏览器开发者工具,还有许多第三方调试工具,如 Visual Studio Code 的调试功能、Chrome 插件等。
调试是一个迭代的过程,通常需要结合多种方法来定位和解决问题。随着经验的积累,你会更熟练地使用这些工具和技巧。
解释一下webworker
https://blog.csdn.net/weixin_37680520/article/details/117623499
https://blog.csdn.net/chenyajundd/article/details/137033829
JavaScript是单线程模型,即所有任务只能在同一个线程上面完成
Web Worker 的作用,就是为 JavaScript** 创造多线程环境**,允许主线程创建 Worker 线程,将一些任务分配给后者运行。
Web Worker 有以下几个使用注意点。
(1)同源限制
分配给 Worker 线程运行的脚本文件,必须与主线程的脚本文件同源。
(2)DOM 限制
Worker 线程所在的全局对象,与主线程不一样,无法读取主线程所在网页的 DOM 对象,也无法使用document、window、parent这些对象。但是,Worker 线程可以navigator对象和location对象。
(3)通信联系
Worker 线程和主线程不在同一个上下文环境,它们不能直接通信,必须通过消息完成。
(4)脚本限制
Worker 线程不能执行alert()方法和confirm()方法,但可以使用 XMLHttpRequest 对象发出 AJAX 请求。
(5)文件限制
Worker 线程无法读取本地文件,即不能打开本机的文件系统(file://),它所加载的脚本,必须来自网络。
如何使用web worker
发送消息 : postMessage
接收消息 : onmessage
拓展
Web Workers 是一种在 Web 应用程序中进行多线程编程的机制。它允许你在后台线程中运行 JavaScript 代码,而不会干扰主线程的执行。这意味着你可以在不阻塞用户界面的情况下执行计算密集型任务。
以下是 Web Workers 的一些关键点:
-
线程隔离:Web Workers 运行在与主线程(UI 线程)隔离的环境中。这种隔离确保了 Worker 内的脚本错误不会导致主线程崩溃,同时也避免了 Worker 访问 DOM 的能力,因为它们在不同的执行环境中运行。
-
通信:主线程和 Worker 之间通过消息传递进行通信。你可以使用
postMessage()方法发送消息,并通过监听message事件来接收消息。这种机制是双向的,允许两个线程之间交换数据。 -
不访问 DOM:由于 Web Workers 运行在后台线程,它们没有权限直接访问 DOM。如果需要与 DOM 交互,你必须在主线程中执行这些操作,然后通过消息传递与 Worker 共享结果。
-
生命周期:你可以使用
Worker构造函数创建一个新的 Worker,然后通过调用它的terminate()方法来终止它。当 Worker 执行完毕或者被终止时,它会自动清理资源。 -
用途:Web Workers 适用于执行那些需要大量计算的任务,比如数据分析、视频处理、音频处理、复杂的图形渲染等,而不会导致用户界面变得不响应。
-
限制:每个 Worker 都有自己的全局上下文,这意味着它们有自己的变量和全局对象。但是,Worker 不能共享全局变量或者全局对象(如
window或document)。 -
同源策略:Web Workers 受到同源策略的限制,即它们只能加载与主页面相同来源的脚本。
-
性能考虑:虽然 Web Workers 可以提高性能,但它们也有自己的开销。创建和通信都涉及到一定的性能成本,因此应该明智地使用,避免过度使用。
下面是一个简单的 Web Workers 示例:
// main.js
// 创建一个新的 Worker
const myWorker = new Worker('worker.js');
// 接收来自 Worker 的消息
myWorker.onmessage = function(e) {
console.log('Message received from worker', e.data);
};
// 发送消息给 Worker
myWorker.postMessage('Hello, worker!');
// worker.js
// 接收来自主线程的消息
self.onmessage = function(e) {
console.log('Message received from main script', e.data);
// 做一些计算...
// 发送消息回主线程
self.postMessage('Hi, main script!');
};
在这个例子中,主线程创建了一个 Worker,并发送了一条消息。Worker 接收消息,处理它,然后回复主线程。主线程监听 message 事件来接收 Worker 的响应。
1. 主线程采用new命令,调用Worker()构造函数,新建一个 Worker 线程。
var worker = new Worker('./work.js');
2. 主线程调用worker.postMessage()方法,向 Worker 发消息。
worker.postMessage('Hello World');
它可以是各种数据类型,包括二进制数据。
3. 主线程通过worker.onmessage指定监听函数,接收子线程发回来的消息。
worker.onmessage = function (event) {
console.log('Received message ' + event.data);
doSomething();
}
function doSomething() {
// 执行任务
worker.postMessage('Work done!');
}
// 这里的worker.onmessage 也可以换成self.addEventListener ,self代表子线程自身,即子线程的全局对象 等同于
self.addEventListener('message', function (e) {
self.postMessage('You said: ' + e.data);
}, false);
4. Worker 完成任务以后,主线程就可以把它关掉。
worker.terminate();
5. Worker 内部如果要加载其他脚本,有一个专门的方法importScripts()。
importScripts('script1.js', 'script2.js');
6. 主线程可以监听 Worker 是否发生错误。如果发生错误,Worker 会触发主线程的error事件。
worker.onerror(function (event) {
console.log([
'ERROR: Line ', e.lineno, ' in ', e.filename, ': ', e.message
].join(''));
});
// 或者
worker.addEventListener('error', function (event) {
// ...
});
Navigator -Javascript navigator对象详解
https://blog.csdn.net/cuclife/article/details/139061021
https://blog.csdn.net/cuclife/article/details/139061021
navigator对象是JavaScript中的一个内置对象,它提供了有关浏览器的信息。
帮助开发者检测用户的浏览器环境,从而实现浏览器兼容性处理或者功能检测。
一、属性和方法概览
-
navigator.appCodeName: 返回浏览器的代码名,通常为"Mozilla"。 -
navigator.appName: 返回浏览器的名称,如"Microsoft Internet Explorer"。 -
navigator.appVersion: 返回浏览器的平台和版本信息。 -
navigator.userAgent: 返回用户代理字符串,包含浏览器类型、版本号及操作系统等信息。 -
navigator.platform: 返回运行浏览器的操作系统平台。 -
navigator.language: 返回用户的首选语言。 -
navigator.cookieEnabled: 告诉你浏览器是否支持并启用了cookie。 -
navigator.onLine: 表示用户当前是否在线。 -
navigator.geolocation: 提供了地理定位的功能(如果浏览器支持的话)。 -
navigator.vendor: 返回浏览器供应商名称。 -
…还有更多,比如与硬件相关的属性(比如
navigator.hardwareConcurrency查询CPU核心数,但使用需谨慎考虑隐私问题)。
三、注意事项
-
隐私与安全:使用
navigator中的某些属性(如geolocation)时,应确保遵循用户的隐私偏好和相关法律法规,提供明确的用户许可请求。 -
一致性问题:不同浏览器对
navigator对象的支持程度和返回值可能有差异,编写代码时应考虑这些差异,尽量采用广泛兼容的特性。 -
User-Agent嗅探:虽然可以通过
navigator.userAgent进行浏览器或设备的简单识别,但这种方法不鼓励用于功能检测,因为User-Agent可以被轻易篡改,且现代Web开发更推荐使用特性检测(Feature Detection)而非浏览器嗅探。 -
性能考量:频繁访问某些
navigator属性可能影响性能,特别是像navigator.hardwareConcurrency这样可能涉及复杂计算的属性。
三种事件模型是什么?
拓展
在 JavaScript 中,事件模型指的是事件的触发、处理和分发的方式。主要有三种事件模型:
- DOM 0 级事件模型:
-
这是最古老的事件模型,直接绑定事件处理器到元素上。
-
没有事件监听器的概念,而是直接将函数赋值给 HTML 元素的事件属性。
-
这种方式的缺点是同一个元素的同一个事件只能绑定一个处理函数,而且不支持捕获和冒泡阶段。
-
示例:
document.getElementById('myButton').onclick = function() {
alert('Button clicked!');
};
- DOM 2 级事件模型:
-
也称为 DOM Level 2 Events,引入了事件监听器的概念。
-
支持
addEventListener方法,可以为元素添加多个事件处理器,并且可以指定事件处理的三个阶段:无捕获(bubble)、捕获(capture)和冒泡(bubbling)。 -
可以使用
removeEventListener方法移除事件处理器。 -
示例:
var button = document.getElementById('myButton');
button.addEventListener('click', function() {
alert('Button clicked!');
}, false); // false 表示在冒泡阶段执行
- IE 事件模型:
-
这是 Internet Explorer 浏览器特有的事件模型,与其他浏览器的 DOM 事件模型有所不同。
-
IE 事件模型使用
attachEvent方法来绑定事件处理器,使用detachEvent方法来移除事件处理器。 -
IE 事件模型中的事件对象 (
event) 不是通过参数传递给事件处理器的,而是作为全局window.event对象。 -
示例:
var button = document.getElementById('myButton');
button.attachEvent('onclick', function() {
alert('Button clicked!');
});
在现代 Web 开发中,推荐使用 DOM 2 级事件模型,因为它提供了更多的灵活性和控制能力。同时,为了兼容不支持 DOM 2 级事件模型的旧版 IE 浏览器,开发者可能需要使用 polyfills 或其他兼容性解决方案。
需要注意的是,随着 Web 标准的不断发展,旧版的 IE 浏览器已经逐渐被淘汰,现代浏览器都支持 DOM 2 级事件模型。因此,DOM 2 级事件模型现在是事实上的标准,并且在现代 Web 开发中被广泛使用。
TypeScript
type和interface的区别
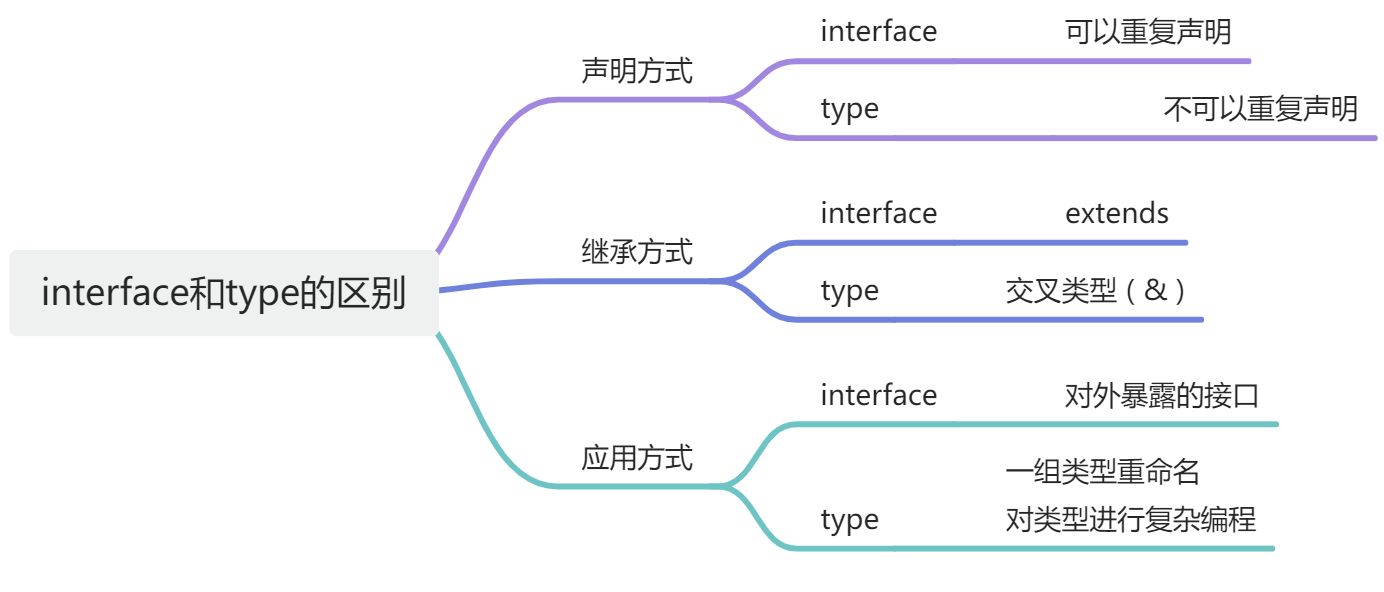
interface可以重复声明,type不行,
继承方式不一样,type使用交叉类型方式(&),interface使用extends实现。
在对象扩展的情况下,使用接口继承要比交叉类型的性能更好。
建议使用interface来描述对象对外暴露的借口,
使用type将一组类型重命名(或对类型进行复杂编程)。
interface iMan {
name: string;
age: number;
}
// 接口可以进行声明合并
interface iMan {
hobby: string;
}
type tMan = {
name: string;
age: number;
};
// type不能重复定义
// type tMan = {}
// 继承方式不同,接口继承使用extends
interface iManPlus extends iMan {
height: string;
}
// type继承使用&,又称交叉类型
type tManPlus = { height: string } & tMan;
const aMan: iManPlus = {
name: "aa",
age: 15,
height: "175cm",
hobby: "eat",
};
const bMan: tManPlus = {
name: "bb",
age: 15,
height: "150cm",
};
any、unkonwn、never
- any和unkonwn在TS类型中属于最顶层的Top Type*,即所有的类型都是它俩的子类型。
而never则相反,它作为Bottom Type是所有类型的子类型。
常见的工具类型
-
Partial:满足部分属性(一个都没满足也可)即可
-
Required:所有属性都需要
-
Readonly: 包装后的所有属性只读
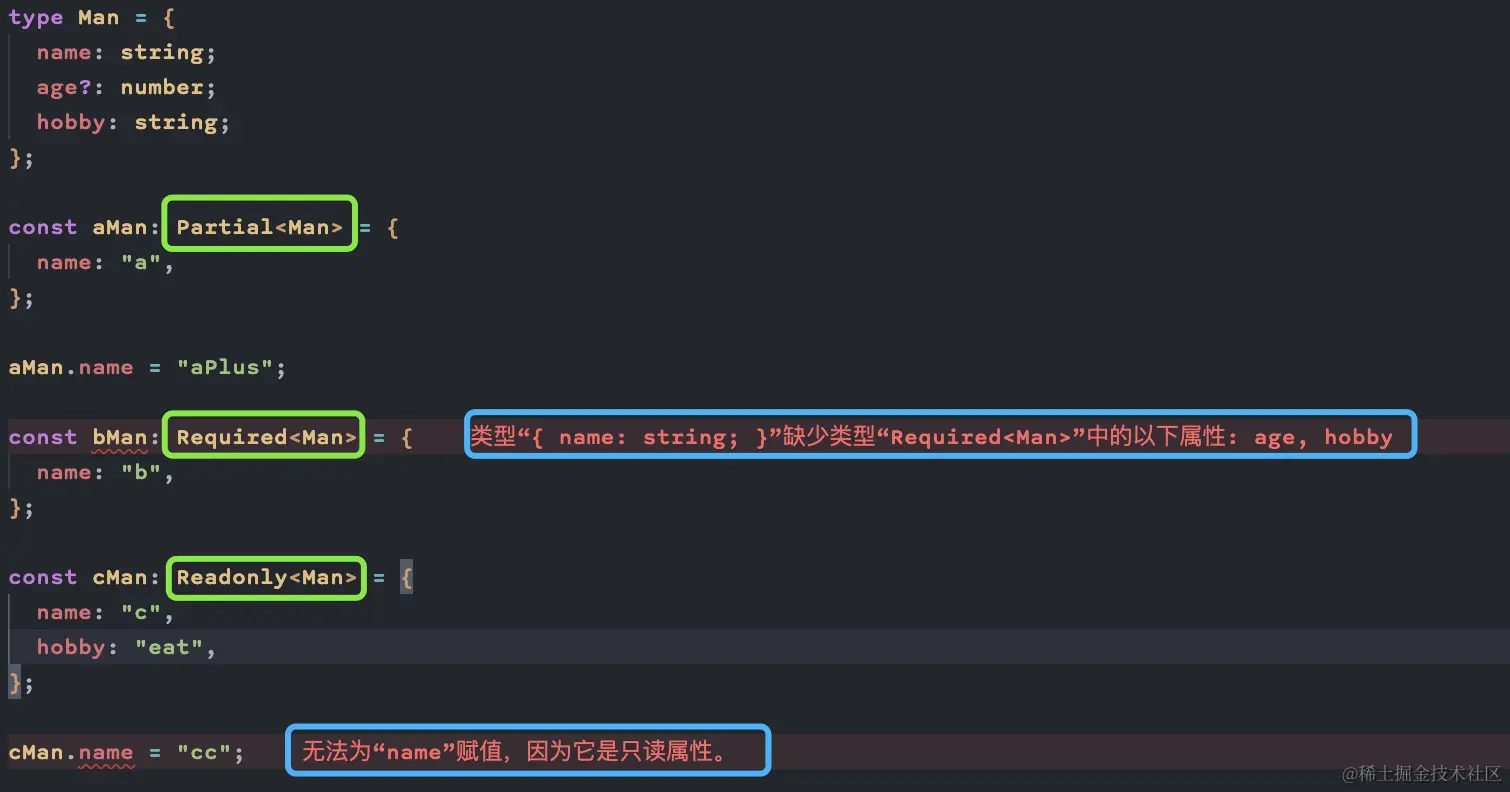
-
Pick: 选取部分属性
-
Omit: 去除部分属性
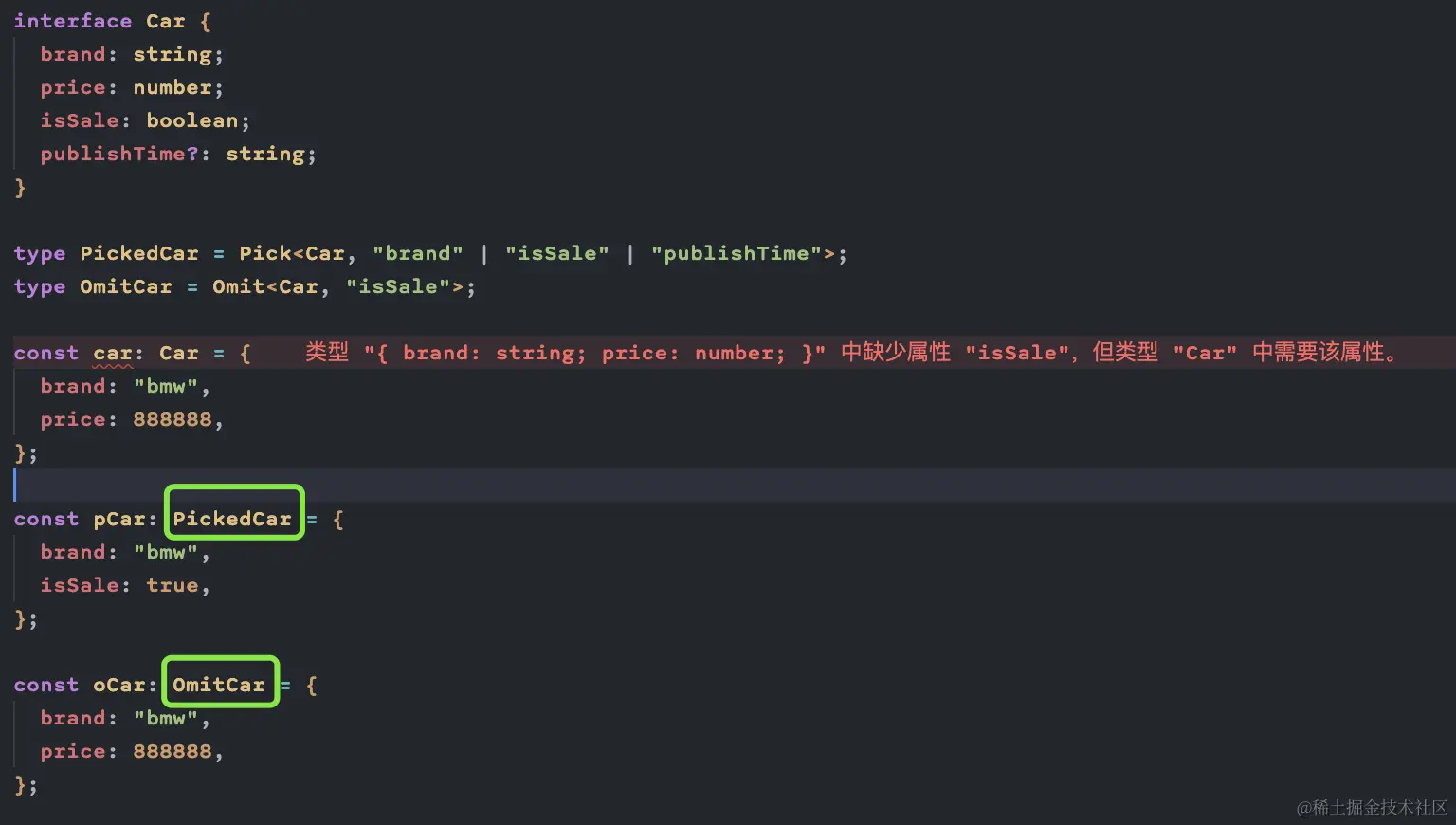
-
Extract: 交集
-
Exclude: 差集
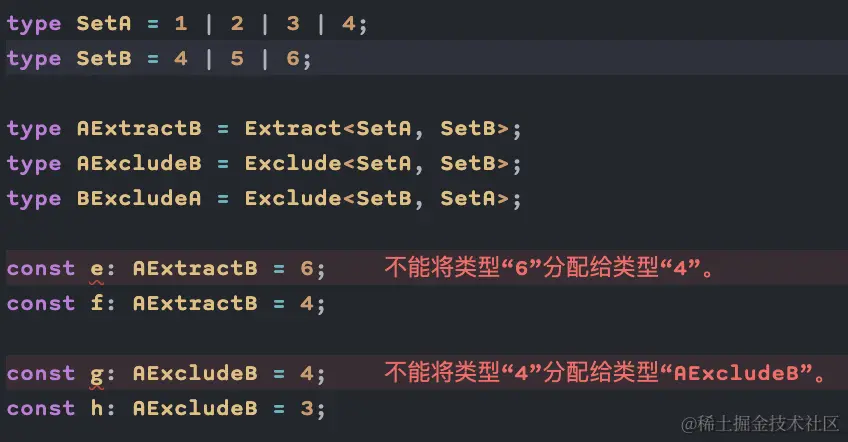
关于 Vue
虚拟dom
虚拟DOM就是用Js来模拟出DOM结构,通过diff算法来计算出最小的变更,通过对应的渲染器,来渲染到页面上。
同时虚拟DOM也为跨平台开发提供了极大的便利,开发者写的同一套代码(有些需要针对不同平台做区分),通过不同的渲染规则,就可以生成不同平台的代码。
在vue中会通过渲染器来将虚拟DOM转换为对应平台的真实DOM。如renderer(vnode, container),该方法会根据vnode描述的信息(如tag、props、children)来创建DOM元素,根据规则为对应的元素添加属性和事件,处理vnode下的children。
双端diff算法和快速diff算法

在Vue.js框架中,虚拟DOM的diff算法是用于比较新旧虚拟DOM树差异的核心机制,目的是为了高效地更新真实DOM。Vue 2和Vue 3在diff算法上有所不同,Vue 2使用的是双端diff算法,而Vue 3则引入了快速diff算法。
Vue 2的双端diff算法
双端diff算法(Two-way diff)是一种在两端同时进行对比的算法。它从新旧两个虚拟DOM列表的头部和尾部开始,向中间进行扫描,寻找相同key的节点,并对这些节点进行更新或移动。这种方法可以减少不必要的DOM操作,但仍然存在一些性能瓶颈,尤其是在处理大量节点或复杂列表时。
Vue 3的快速diff算法
Vue 3引入了快速diff算法,这是一种更高效的算法,它借鉴了纯文本diff算法的思想。快速diff算法在处理新旧节点列表时,会先进行预处理,找出可以确定无需比较的相同前后缀节点,然后只对中间不确定的部分进行深入比较。这种方法可以进一步减少不必要的DOM操作,提高性能。
快速diff算法的核心在于使用了一个名为source数组来记录新节点的位置索引,并通过构建最长递增子序列(Longest Increasing Subsequence, LIS)来确定哪些节点需要移动。这种方法相比双端diff算法,处理的边际条件更少,性能更优。
总结
Vue 3的快速diff算法相比Vue 2的双端diff算法,在处理复杂列表更新时,能够提供更好的性能。它通过预处理和最长递增子序列的构建,减少了不必要的DOM操作,使得渲染更新更加高效。这种算法的改进是Vue 3性能提升的一个重要方面。
vue2和vue3有哪些不同
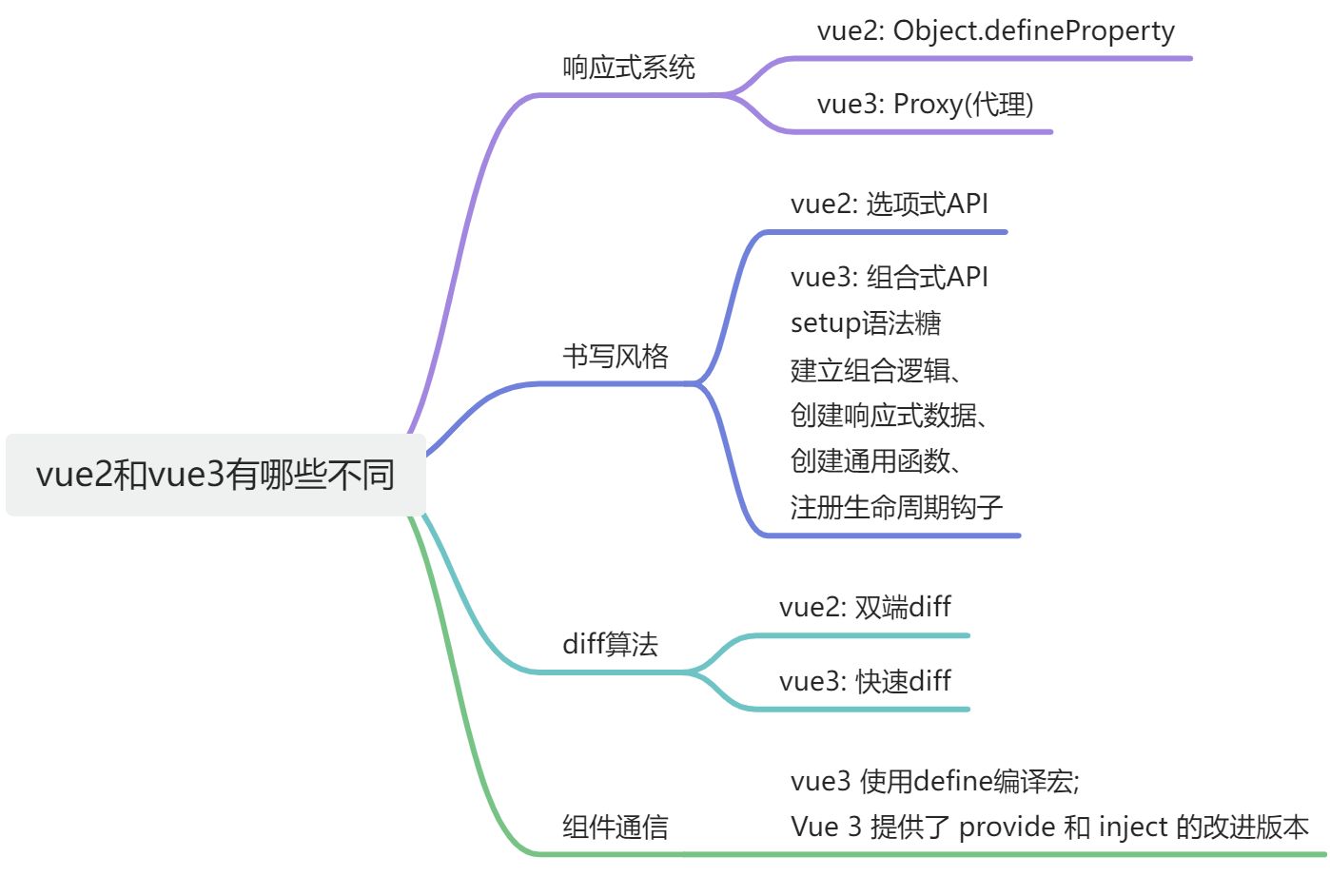
Vue 2 和 Vue 3 都是流行的前端框架 Vue.js 的主要版本,它们在功能、性能和语法上有一些显著的差异。以下是 Vue 2 和 Vue 3 之间的一些主要区别:
- 响应式系统的重写:
-
Vue 2 使用的是
defineProperty(Object.defineProperty)来实现响应式系统。 -
Vue 3 引入了基于 Proxy 的响应式系统,这使得 Vue 3 能够更高效地追踪依赖和更新视图。
- Composition API:
- Vue 3 引入了 Composition API,这是一种新的编写组件逻辑的方式,它提供了更好的代码组织和复用性,特别是在处理复杂组件时。
- Fragment、Teleport 和 Suspense:
- Vue 3 引入了新的内置组件,如
Fragment(允许多个根节点)、Teleport(可以将组件的子节点传输到 DOM 的其他部分)和Suspense(用于异步组件的加载状态处理)。
- 性能提升:
- Vue 3 在虚拟 DOM 的重写、组件初始化、编译器优化等方面都进行了性能提升。
- Tree-shaking 支持:
- Vue 3 的模块化系统更好地支持了 Tree-shaking,这意味着在最终的构建中可以移除未使用的代码,从而减少应用的大小。
- 自定义渲染器 API:
- Vue 3 提供了更灵活的自定义渲染器 API,允许开发者创建自定义的渲染器。
- 全局 API 的更改:
- Vue 3 对全局 API 进行了更改,例如
Vue.prototype被app.config.globalProperties替代。
- 模板和组件的改进:
- Vue 3 改进了模板编译器,支持更广泛的 JavaScript 特性,并允许在
<script>标签中使用新的语法。
- TypeScript 支持:
- Vue 3 的代码库使用 TypeScript 重写,提供了更好的类型推断和类型检查。
- 内部重构:
- Vue 3 进行了大规模的内部重构,包括虚拟 DOM 的重写和响应式系统的改进。
- 新的生命周期钩子:
- Vue 3 引入了一些新的生命周期钩子,如
onBeforeMount、onMounted、onBeforeUpdate、onUpdated、onBeforeUnmount和onUnmounted。
- 更好的组件通信:
- Vue 3 提供了
provide和inject的改进版本,使得跨组件的状态共享更加方便。
这些改进使得 Vue 3 在性能、可维护性和开发体验上都有了显著的提升。开发者在升级到 Vue 3 时,需要对这些变化有所了解,并可能需要对现有的代码进行一些调整。
vue3双向绑定实现
劫持数据 Proxy
依赖收集 get
派发更新 set
// WeakMap常用于存储只有当key所引用的对象存在时(没有被回收)才有价值的消息,十分贴合双向绑定场景
const bucket = new WeakMap(); // 存储副作用函数
let activeEffect; // 用一个全局变量处理被注册的函数
const tempObj = {}; // 临时对象,用于操作
const data = { text: "hello world" }; // 响应数据源
// 用于清除依赖
function cleanup(effectFn) {
for (let i = 0; i < effectFn.deps.length; i++) {
const deps = effectFn.deps[i];
deps.delete(effectFn);
}
effectFn.deps.length = 0;
}
// 处理依赖函数
function effect(fn) {
const effectFn = () => {
cleanup(effectFn);
activeEffect = effectFn;
fn();
};
effectFn.deps = [];
effectFn();
}
// 在get时拦截函数调用track函数追踪变化
function track(target, key) {
if (!activeEffect) return; //
let depsMap = bucket.get(target);
if (!depsMap) {
bucket.set(target, (depsMap = new Map()));
}
let deps = depsMap.get(key);
if (!deps) {
depsMap.set(key, (deps = new Set()));
}
deps.add(activeEffect);
activeEffect.deps.push(deps);
}
// 在set拦截函数内调用trigger来触发变化
function trigger(target, key) {
const depsMap = bucket.get(target);
if (!depsMap) return;
const effects = depsMap.get(key);
const effectsToRun = new Set(effects);
effectsToRun.forEach(effectFn => effectFn());
// effects && effects.forEach(fn => fn());
}
const obj = new Proxy(data, {
// 拦截读取操作
get(target, key) {
if (!activeEffect) return; //
console.log("get -> key", key);
track(target, key);
return target[key];
},
// 拦截设置操作
set(target, key, newValue) {
console.log("set -> key: newValue", key, newValue);
target[key] = newValue;
trigger(target, key);
},
});
effect(() => {
tempObj.text = obj.text;
console.log("tempObj.text :>> ", tempObj.text);
});
setTimeout(() => {
obj.text = "hi vue3";
}, 1000);
vue3中的ref、toRef、toRefs总结
总结
-
ref用于创建单一值的响应式引用。 -
toRef用于创建对象某个属性的响应式引用。 -
toRefs用于将响应式对象的每个属性转换为响应式引用。 -
computed和watch的区别
拓展
在 Vue 3 中,响应式系统得到了重写,引入了基于 Proxy 的 API,这使得 Vue 3 的响应式特性更加强大和灵活。ref、toRef 和 toRefs 是 Vue 3 中与响应式系统相关的几个重要函数,它们在 Composition API 中扮演着关键角色。
ref
ref 是一个用于创建响应式引用的函数。它接受一个值作为参数,并返回一个包含 .value 属性的响应式对象。这个对象的 .value 属性指向原始值,并且当原始值改变时,任何依赖于该响应式引用的组件都会重新渲染。
import { ref } from 'vue';
const count = ref(0); // 创建一个响应式引用
在模板中使用时,可以直接访问 .value 属性:
<template>
<div>{{ count.value }}</div>
</template>
或者在 Vue 3.2 及更高版本中,可以使用 v-model 指令的 modelValue 和 "update:modelValue" 事件进行更简洁的绑定:
<template>
<input v-model="count" />
</template>
toRef
toRef 用于创建一个响应式引用,但它是针对对象的某个属性。当你有一个响应式对象,并想要创建一个仅针对其某个属性的响应式引用时,可以使用 toRef。
import { toRef } from 'vue';
const state = reactive({ count: 0 });
const countRef = toRef(state, 'count'); // 创建一个仅针对 state.count 的响应式引用
这样,countRef 将仅追踪 state 对象中 count 属性的变化。
toRefs
toRefs 用于将一个响应式对象转换为一个包含多个响应式引用的对象。这在处理由 reactive 创建的响应式对象时非常有用,因为它允许你保留每个属性的响应性。
import { toRefs } from 'vue';
const state = reactive({ count: 0, name: 'Vue' });
const { count, name } = toRefs(state);
现在,count 和 name 都是响应式引用,它们的更新将触发依赖它们的组件重新渲染。
总结
-
ref用于创建单一值的响应式引用。 -
toRef用于创建对象某个属性的响应式引用。 -
toRefs用于将响应式对象的每个属性转换为响应式引用。。这些函数是 Vue 3 Composition API 的基础,它们提供了一种灵活的方式来处理响应式数据。
computed和watch的区别
使用场景:computed适用于一个数据 受多个数据影响 使用;
watch适合一个数据 影响 多个数据使用。
区别:computed属性默认会走缓存,只有依赖数据发生变化,才会重新计算,不支持异步,有异步导致数据发生变化时,无法做出相应改变;
watch不依赖缓存,一旦数据发生变化就直接触发响应操作,支持异步。
vue-router的路由守卫
- 全局前置守卫
router.beforeEach((to, from, next) => {
// to: 即将进入的目标
// from:当前导航正要离开的路由
return false // 返回false用于取消导航
return {name: 'Login'} // 返回到对应name的页面
next({name: 'Login'}) // 进入到对应的页面
next() // 放行
})
- 全局解析守卫:类似beforeEach
router.beforeResolve(to => {
if(to.meta.canCopy) {
return false // 也可取消导航
}
})
- 全局后置钩子
router.afterEach((to, from) => {
logInfo(to.fullPath)
})
- 导航错误钩子,导航发生错误调用
router.onError(error => {
logError(error)
})
- 路由独享守卫,beforeEnter可以传入单个函数,也可传入多个函数。
function dealParams(to) {
// ...
}
function dealPermission(to) {
// ...
}
const routes = [
{
path: '/home',
component: Home,
beforeEnter: (to, from) => {
return false // 取消导航
},
// beforeEnter: [dealParams, dealPermission]
}
]
- 组件内的守卫*
const Home = {
template: `...`,
beforeRouteEnter(to, from) {
// 此时组件实例还未被创建,不能获取this
},
beforeRouteUpdate(to, from) {
// 当前路由改变,但是组件被复用的时候调用,此时组件已挂载好
},
beforeRouteLeave(to, from) {
// 导航离开渲染组件的对应路由时调用
}
}
composition Api对比 option Api的优势
-
更好的代码组织
-
-组合式API
-
更好的逻辑复用
-
-Hooks钩子函数 及 替代mixin的 自定义的use 前缀的 Hooks
-
更好的类型推导
-
-TS
浏览器相关
跨域问题
-
配置nginx反向代理
-
使用jsonp方式(script方式)
-
使用图片
-
设置CORS(跨域资源共享)
-
利用iframe实现
-
WebSocket
https://blog.csdn.net/m0_70705683/article/details/138483558
https://blog.csdn.net/m0_70705683/article/details/138483558
拓展
跨域问题(Cross-Origin Resource Sharing,CORS)是 Web 开发中常见的一个安全问题,它源于浏览器的同源策略(Same-Origin Policy)。同源策略是一种安全措施,用于限制一个域(域、协议和端口)的文档或脚本如何与另一个域的资源进行交互。这是为了防止恶意文档访问数据,从而保护用户的信息安全。
跨域问题的原因
当一个网页尝试请求另一个域的资源时,如果这两个域的协议、域名或端口不一致,就会触发浏览器的同源策略,导致跨域问题。
常见的跨域场景
-
Ajax 请求:从前端页面发起的 XMLHttpRequest 或 Fetch 请求,请求不同域的 API。
-
Web Fonts:加载不同域的字体资源。
-
Canvas:在 canvas 中加载不同域的图片。
-
视频和音频:尝试播放不同域的视频或音频文件。
解决跨域问题的方法
- CORS 头部:
-
服务器可以通过设置 HTTP 响应头
Access-Control-Allow-Origin来允许特定的外部域访问资源。 -
例如:
Access-Control-Allow-Origin: *(允许所有域)或Access-Control-Allow-Origin: https://example.com(只允许指定域)。
- JSONP(已过时):
- 通过动态创建
<script>标签的方式来绕过同源策略,但由于安全性和功能限制,这种方法已逐渐被废弃。
- 代理服务器:
- 在客户端和目标服务器之间设置一个代理服务器,客户端向代理服务器发送请求,代理服务器再向目标服务器请求数据,然后将数据返回给客户端。
- 文档域设置:
- 通过设置
document.domain来允许具有相同主域但不同子域的页面之间进行交互。
- WebSockets:
- WebSockets 协议不受同源策略的限制,可以用于跨域通信。
- PostMessage:
- HTML5 提供的
window.postMessage方法可以安全地实现跨源通信。
- CORS 任何域:
- 使用
Access-Control-Allow-Origin: *可以允许任何域的请求,但要注意这可能会带来安全风险。
注意事项
-
在配置 CORS 时,应该尽量避免使用
Access-Control-Allow-Origin: *,因为这可能会使你的资源对所有网站开放,增加安全风险。 -
在实际开发中,应该根据实际需求来设置合适的 CORS 策略,例如只允许特定的域名访问。
跨域问题是一个复杂的安全问题,需要根据具体的应用场景和安全需求来选择合适的解决方案。
浏览器的存储有哪些及它们间的区别
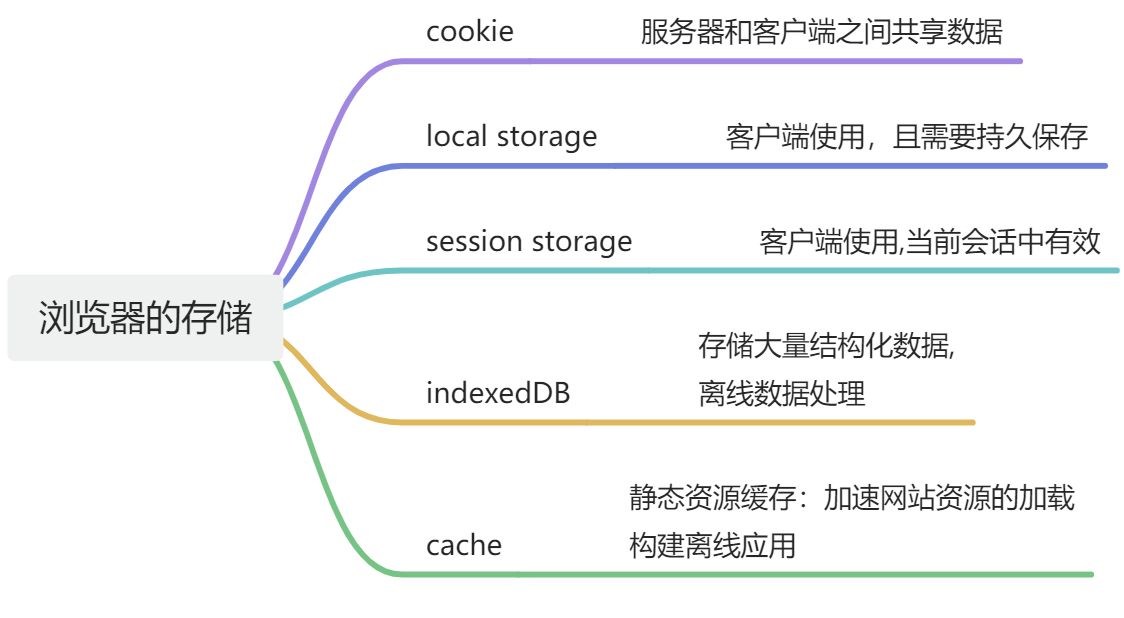
-
cookie
-
session storage
-
local storage
-
indexedDB:用于客户端存储大量的结构化数据(文件/二进制大型对象(blobs))。该API使用索引实现对数据的高性能搜索。
-
cache storage:用于对Cache对象的存储。
- Cookies vs. Local Storage vs. Session Storage:
-
如果需要在服务器和客户端之间共享数据,使用 Cookies。
-
如果数据仅在客户端使用,且需要持久保存,使用 Local Storage。
-
如果数据仅在当前会话中有效,使用 Session Storage。
- IndexedDB:
-
复杂数据存储和查询:存储大量结构化数据,如用户数据库、产品目录等。
-
性能要求高的应用:对于需要高性能读写操作的应用,如实时通讯应用。
-
离线数据处理:在离线状态下处理和分析大量数据。
- Cache API:
-
静态资源缓存:加速网站资源的加载,提高用户体验。
-
构建离线应用:缓存应用的外壳和关键资源,实现离线访问。
-
网络状况不佳时的内容提供:在用户网络连接不佳时提供缓存的内容。
拓展 浏览器的存储有哪些及它们间的区别
浏览器提供了多种存储数据的方式,每种方式都有其特点和用途。以下是常见的浏览器存储方式及其区别:
- Cookies:
-
存储在用户的浏览器中,由服务器创建,每次请求都会发送到服务器。
-
通常用于存储会话信息,如用户认证状态。
-
有大小限制(一般为4KB)。
-
可以设置过期时间,分为会话 Cookie 和持久 Cookie。
- Local Storage:
-
存储在用户的浏览器中,仅在客户端存储数据。
-
存储容量较大(一般为5MB左右)。
-
数据持久保存,即使关闭浏览器窗口后数据也不会消失。
-
只能存储字符串,存储时需要将对象转换为 JSON 字符串。
- Session Storage:
-
与 Local Storage 类似,但数据仅在当前浏览器窗口(或标签页)中有效。
-
数据在页面会话期间有效,关闭窗口或标签页后数据会被清除。
-
同样只能存储字符串。
- IndexedDB:
-
是一种低级 API,允许存储大量结构化数据。
-
支持事务,可以对数据进行更复杂的查询和操作。
-
存储容量大(一般无限制,但受浏览器和用户磁盘空间限制)。
-
可以存储包括文件/blobs在内的多种数据类型。
- Web SQL(已不推荐使用):
-
提供了一个类似于 SQLite 的 SQL 数据库,允许执行 SQL 语句进行数据存储和检索。
-
由于性能和安全问题,Web SQL 已被许多现代浏览器弃用。
- Cache API(Service Workers):
-
与 Service Workers 一起使用,允许缓存文件(如 HTML、CSS、JavaScript、图片等)。
-
用于实现离线体验和加快页面加载速度。
-
可以精确控制缓存的内容和缓存策略。
- Cookies vs. Local Storage vs. Session Storage:
-
Cookies 通常与服务器交互,而 Local Storage 和 Session Storage 仅在客户端存储数据。
-
Local Storage 的存储容量大于 Cookies,且数据持久保存。
-
Session Storage 的数据只在当前会话中有效,关闭浏览器窗口或标签页后数据会被清除。
- LocalStorage vs. SessionStorage:
- Local Storage 的数据在页面会话之间持久保存,而 Session Storage 的数据只在当前会话中有效。
选择合适的存储方式取决于应用的需求,例如数据的大小、是否需要跨会话持久保存、是否需要与服务器交互等。
常用场景
不同的浏览器存储方式适用于不同的场景,以下是一些常用场景的举例:
- Cookies:
-
用户登录状态的保持:存储用户的会话标识(session ID)。
-
个性化设置:保存用户的首选语言、主题或其他偏好设置。
-
购物车数据:在用户浏览电子商务网站时临时保存商品信息。
- Local Storage:
-
离线应用数据存储:用于构建需要离线支持的 Web 应用。
-
表单自动填充:保存用户之前填写的表单数据,以便下次自动填充。
-
游戏状态保存:在基于浏览器的游戏中保存玩家进度。
- Session Storage:
-
表单页面之间的数据传递:在同一表单的不同页面间传递数据。
-
临时数据存储:保存只在当前会话中需要的数据,如用户在填写表单过程中的临时数据。
- IndexedDB:
-
复杂数据存储和查询:存储大量结构化数据,如用户数据库、产品目录等。
-
性能要求高的应用:对于需要高性能读写操作的应用,如实时通讯应用。
-
离线数据处理:在离线状态下处理和分析大量数据。
- Cache API:
-
静态资源缓存:加速网站资源的加载,提高用户体验。
-
构建离线应用:缓存应用的外壳和关键资源,实现离线访问。
-
网络状况不佳时的内容提供:在用户网络连接不佳时提供缓存的内容。
- Web SQL (已不推荐使用):
- 尽管已被弃用,但之前它适用于需要使用 SQL 语句进行数据存储和查询的场景。
- Cookies vs. Local Storage vs. Session Storage:
-
如果需要在服务器和客户端之间共享数据,使用 Cookies。
-
如果数据仅在客户端使用,且需要持久保存,使用 Local Storage。
-
如果数据仅在当前会话中有效,使用 Session Storage。
- LocalStorage vs. SessionStorage:
-
对于需要跨会话持久保存的数据,使用 Local Storage。
-
对于仅在当前会话或标签页中有效的临时数据,使用 Session Storage。
选择最合适的存储方式可以提高应用的性能和用户体验,同时减少不必要的服务器负载。
应用场景代码
下面是一些示例代码,展示如何在不同场景中使用浏览器的存储方式:
Cookies
- 设置 Cookie*:
document.cookie = "username=John Doe; expires=Thu, 18 Dec 2023 12:00:00 UTC; path=/";
- 读取 Cookie*:
function getCookie(name) {
let cookieArray = document.cookie.split(';');
let cookie = cookieArray.find(row => row.trim().startsWith(name + "="));
return cookie ? cookie.split('=')[1] : null;
}
let username = getCookie('username');
Local Storage
- 存储数据*:
localStorage.setItem('username', 'John Doe');
- 读取数据*:
let username = localStorage.getItem('username');
- 移除数据*:
localStorage.removeItem('username');
Session Storage
- 存储数据*:
sessionStorage.setItem('sessionToken', 'abc123');
- 读取数据*:
let sessionToken = sessionStorage.getItem('sessionToken');
- 移除数据*:
sessionStorage.removeItem('sessionToken');
IndexedDB
- 打开数据库*:
let request = indexedDB.open('myDatabase', 1);
request.onupgradeneeded = function(event) {
let db = event.target.result;
if (!db.objectStoreNames.contains('products')) {
db.createObjectStore('products', { keyPath: 'id' });
}
};
request.onerror = function(event) {
console.error('Database error:', event.target.errorCode);
};
request.onsuccess = function(event) {
let db = event.target.result;
// 可以在这里进行数据库操作
};
- 存储对象*:
let request = db.transaction(['products'], 'readwrite')
.objectStore('products')
.add({ id: 1, name: 'Keyboard', price: 29.99 });
request.onsuccess = function() {
console.log('Product added to the store.');
};
Cache API
- 缓存资源*:
let cache = await caches.open('v1');
await cache.addAll([
'/styles/main.css',
'/script/main.js',
'/images/logo.png'
]);
- 使用缓存*:
self.addEventListener('fetch', function(event) {
event.respondWith(
caches.match(event.request).then(function(response) {
return response || fetch(event.request);
})
);
});
注意事项
-
Cookies 是自动发送到服务器的,而 Local Storage 和 Session Storage 仅在客户端使用。
-
IndexedDB 操作是异步的,需要处理成功、失败和完成的事件。
-
Cache API 通常与 Service Workers 结合使用,以实现离线缓存和性能优化。
这些代码示例提供了如何在不同场景中使用浏览器存储的基本框架。在实际应用中,你可能需要根据具体需求进行调整和扩展。
说说浏览器渲染页面的过程
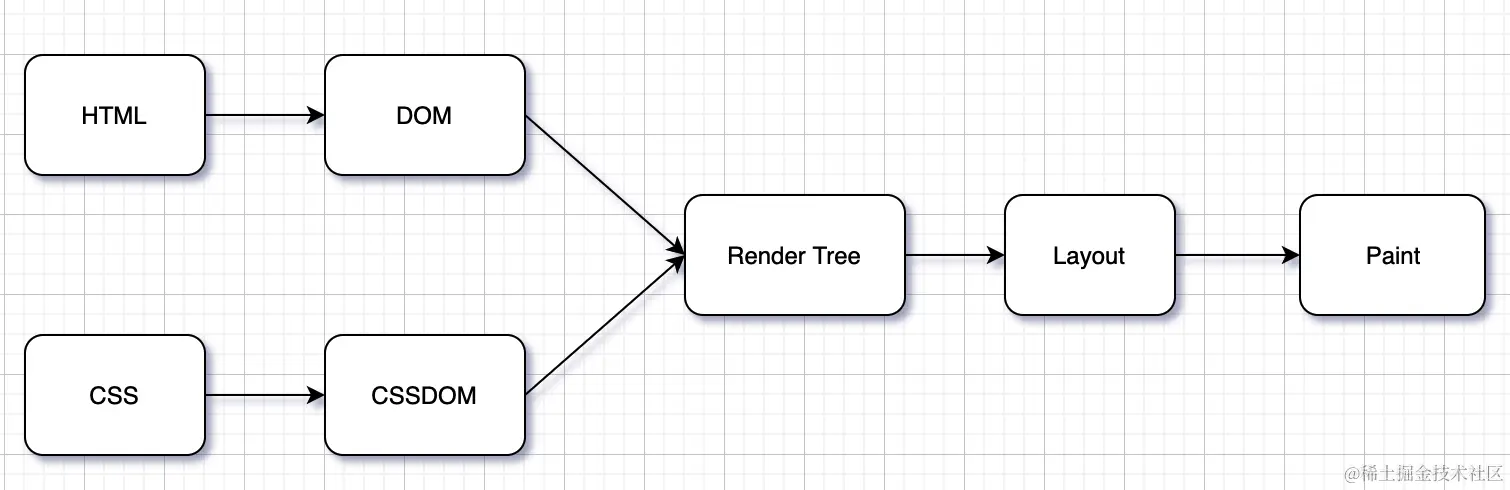
输入网址,浏览器发起DNS请求得到ip地址,
然后进行TCP三次握手建立连接,
浏览器代表用户向服务器发起一个get请求,一般是请求html文件,服务器收到请求,会根据相关响应头和html内容进行回复
浏览器拿到数据就开始解析
解析html构建dom树
解析css构建cssdom
两者构建渲染树( render tree)
布局( layout)
绘制( paint)
加载js文件
- 重排(Reflow)和重绘(Repaint)*
拓展
浏览器渲染页面是一个复杂的过程,涉及到多个阶段,包括解析 HTML、CSS 和 JavaScript 代码,构建 DOM 树、CSSOM 树,以及执行 JavaScript 代码。以下是浏览器渲染页面的大致步骤:
- 解析 HTML:
-
浏览器首先接收到服务器发送的 HTML 文档。
-
浏览器开始解析 HTML 代码,构建 DOM(Document Object Model)树。DOM 树是由节点组成的,每个节点代表 HTML 文档中的一个元素。
- 解析 CSS:
- 浏览器解析外部或内部 CSS 样式表,构建 CSSOM(CSS Object Model)树。CSSOM 树包含了所有 CSS 规则,用于确定页面的样式。
- 构建渲染树:
- 浏览器将 DOM 树和 CSSOM 树合并,构建渲染树(Render Tree)。渲染树包含了页面上所有可见的元素及其样式信息。
- 布局(Layout):
- 浏览器对渲染树进行布局,也称为“流式布局”(Flow Layout)。这一步确定了每个元素在页面上的确切位置和大小。
- 绘制(Painting):
- 浏览器根据渲染树的信息,将每个元素绘制到屏幕上。这一步涉及到实际的像素渲染。
- 合成(Compositing):
- 对于有层叠上下文(z-index, opacity, transform, filters 等属性)的元素,浏览器会进行合成操作。合成是将页面的各个部分按正确的顺序绘制到屏幕上。
- JavaScript 执行:
- 浏览器解析 JavaScript 代码,并执行其中的脚本。JavaScript 可以修改 DOM 树和 CSSOM 树,这可能导致页面的重新渲染。
- 重排(Reflow)和重绘(Repaint):
- 当 DOM 或 CSSOM 发生变化时,浏览器可能需要重新执行布局和绘制过程。重排是重新计算元素的几何信息,重绘是重新将元素绘制到屏幕上。
- 优化:
- 为了提高性能,浏览器会尝试优化这些步骤。例如,浏览器可能会延迟某些重排和重绘操作,或者使用硬件加速来提高渲染性能。
- 回流(Reflow)和重绘:
- 回流是指页面的部分或全部元素的布局发生变化,需要重新计算元素的位置和尺寸。重绘是指页面的部分或全部元素需要重新绘制。回流一定伴随着重绘,但重绘不一定伴随着回流。
浏览器渲染页面的过程是动态的,可能会因为用户交互、JavaScript 事件、网络请求等原因而重复进行。为了提高性能,开发者需要尽量减少重排和重绘的发生,例如通过避免频繁的样式更改、使用文档片段(DocumentFragment)进行批量 DOM 操作等方法。
cookie的属性
https://blog.csdn.net/qq_38290251/article/details/134320911
https://blog.csdn.net/qq_38290251/article/details/134320911
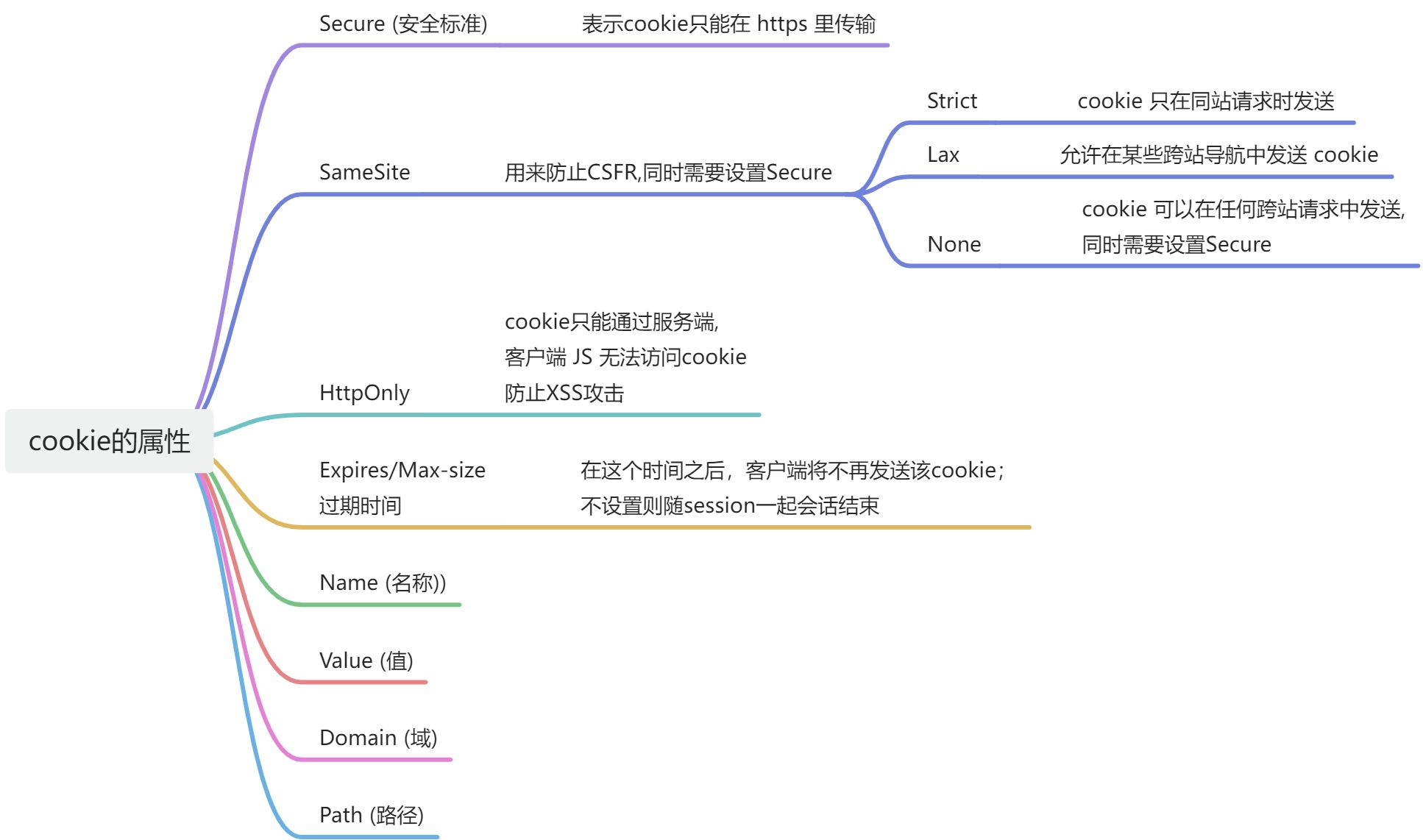
- 结论先行*:
Cookie 中除了名称和值外,还有几个比较常见的,例如:
-
Domain* 域:指定了 cookie 可以发送到哪些域,只有发送到指定域或其子域的请求才会携带该cookie;
-
*Path **路径:指定哪些请求 URL 路径可以访问 cookie,只有在指定的路径下发起的请求才会携带该 cookie;
-
Expires/Max-size* 过期时间:设置 cookie 的过期时间。在这个时间之后,客户端将不再发送该cookie;不设置则随session一起会话结束
-
HttpOnly*:如果设置了这个标志,那只有服务端可以(通过响应头)操作 cookie;客户端(JavaScript ) 将无法操作 cookie,这样可以防止跨站脚本攻击获取到cookie 信息。
-
Secure* 安全标志:如果设置了这个标志,那么cookie 只有在通过 HTTPS 连接时才会发送到服务器。而不会通过 HTTP 协议;
-
SameSite标志*:这个属性用于防止跨站请求伪造(CSRF)。它可以设置为
Strict、Lax或None。Strict表示 cookie 只在同站请求时发送,Lax允许在某些跨站导航中发送 cookie,而None表示 cookie 可以在任何跨站请求中发送,但必须同时设置Secure属性。
拓展
Cookie的基本属性
-
名称(Name):表示Cookie的名称,用于标识存储的信息。
-
值(Value):与Cookie名称相对应的数据。
-
域(Domain):Cookie所属的网站域名,只有来自该域的请求才会携带这个Cookie。
-
路径(Path):Cookie适用的页面路径,只有请求这个路径下的页面时,浏览器才会发送Cookie。
-
过期时间(Expires/Max-Age):Cookie的有效期,Expires是具体的过期日期,而Max-Age是自设置之日起的秒数。
-
安全标志(Secure):表示该Cookie只能在HTTPS连接中传输。
-
HttpOnly标志:表示该Cookie不能被客户端脚本访问,有助于减少跨站脚本攻击(XSS)的风险。
-
SameSite标志:用于控制Cookie的跨站请求行为,防止CSRF攻击。
每个属性的作用和重要性
-
名称(Name):每个Cookie都需要一个唯一的名称,用于区分不同的数据片段。
-
值(Value):存储与名称相对应的具体数据。
-
域(Domain):限制Cookie的使用范围,只有来自指定域的请求才会携带此Cookie。
-
路径(Path):进一步限制Cookie的使用范围,只有请求指定路径下的页面时才会发送此Cookie。
-
过期时间(Expires/Max-Age):设置Cookie的有效期,过期后自动删除。
-
安全标志(Secure):确保Cookie只能通过安全的HTTPS连接传输,防止数据泄露。
-
HttpOnly标志:防止通过JavaScript访问Cookie,减少XSS攻击的风险。
-
SameSite标志:防止CSRF攻击,控制Cookie在跨站请求中的行为。
常用网络状态码以及含义
https://blog.csdn.net/qq_39294511/article/details/136936558
https://blog.csdn.net/qq_39294511/article/details/136936558
以下是常见的网络状态码及其含义:
- 1xx(信息类状态码*):
100 Continue:继续。服务器已经收到客户端的部分请求,客户端可继续发送请求。
101 Switching Protocols:切换协议。服务器正在根据客户端的请求切换协议。
- 2xx(成功类状态码):*
200 OK:请求成功。
201 Created:已创建。请求已成功创建新的资源。
202 Accepted :服务器已接受请求,但尚未处理。
204 No Content:无内容。服务器成功处理请求,但无返回内容。
- 3xx(重定向类状态码):*
301 Moved Permanently:永久重定向。请求的资源已永久移到新位置。
302 Found:临时重定向。请求的资源临时移到新位置。
303 See Other:查看其他位置。请求的资源可以在不同的URI下找到。
304 Not Modified:未修改。客户端缓存的资源是最新的,不需要再次传输。
- 4xx(客户端错误类状态码):*
400 Bad Request:错误请求。服务器无法理解客户端的请求。
401 Unauthorized:未授权。请求需要身份验证。
403 Forbidden:禁止访问。服务器拒绝访问请求的资源。
404 Not Found:未找到。请求的资源不存在。
- 5xx(服务器错误类状态码):*
500 Internal Server Error:内部服务器错误。服务器遇到了未知的错误。
501 Not Implemented:服务器不支持请求的功能,无法完成请求。
502 Bad Gateway:错误网关。服务器作为网关或代理,从上游服务器收到无效的响应。
503 Service Unavailable:服务不可用。服务器当前无法处理请求。
504 Gateway Timeout:网关超时。服务器作为网关或代理,未及时接收到上游服务器的响应。
- 6xx(特定于浏览器类状态码):*
600 Unparseable Response Headers:无法解析的响应头。服务器返回的响应头无法被解析。
以上是常见的网络状态码及其含义,实际使用中可能还有其他状态码。
工具链相关题目
对webpack的理解
Webpack是一个静态模块打包器
通过分析模块之间的依赖生成依赖图来打包文件,通过Loaders将其他(css,图片,字体等)文件转换成js或者json文件( Webpack本身只能处理js或者json文件)
通过一系列配置将打包成一个个bundler
拓展
Webpack 是一个现代 JavaScript 应用程序的静态模块打包器(module bundler)。它将应用程序中的所有依赖项(如 JavaScript 文件、图片、CSS 样式表等)打包成一个或多个 bundle,这些 bundle 可以被浏览器加载和执行。Webpack 被广泛用于前端开发中,特别是在单页应用(SPA)的开发中。
以下是对 Webpack 的一些核心理解:
- 模块化:
- Webpack 鼓励使用模块化的方式来组织代码。每个模块可以是一个 JavaScript 文件、图片、CSS 文件或其他类型的资源。
- 依赖图:
- Webpack 通过分析模块之间的依赖关系,构建出一个依赖图(dependency graph),并根据这个图来打包文件。
- Loaders:
- Webpack 本身只能处理 JavaScript 和 JSON 文件。为了处理其他类型的文件(如 CSS、图片、字体等),Webpack 使用了 loader 来转换这些文件。Loaders 可以在打包过程中预处理文件,例如将 Sass 转换为 CSS,或者将图片转换为DataURL。
- Plugins:
- Webpack 通过插件(plugins)来扩展其核心功能。插件可以执行各种任务,如优化打包后的代码、管理资源、提供热模块替换(HMR)等。
- 入口和出口:
- 在 Webpack 配置中,你需要指定入口(entry)和出口(output)。入口告诉 Webpack 从哪个(些)文件开始打包,出口指定了打包后的文件应该放置在哪里。
- 模式:
- Webpack 支持两种模式:开发模式(development)和生产模式(production)。开发模式通常用于本地开发,提供更快的构建速度和更丰富的调试信息;生产模式用于生成优化后的代码,以提高性能和减少文件大小。
- 代码分割:
- Webpack 支持代码分割(code splitting),这意味着它可以将应用程序分割成多个 bundle,这些 bundle 可以按需加载(懒加载)。这有助于减少初始加载时间,提高应用程序的性能。
- 热模块替换(HMR):
- Webpack 支持热模块替换,这允许在开发过程中,当代码发生变化时,无需刷新页面即可更新模块。
- 构建优化:
- Webpack 提供了多种优化策略,如摇树优化(tree shaking)、模块懒加载、压缩和最小化等,以减少最终构建的大小和提高加载速度。
- 配置文件:
- Webpack 的行为可以通过一个配置文件(通常是
webpack.config.js)来控制。这个配置文件定义了入口点、输出路径、loader 配置、插件列表等。
Webpack 的强大之处在于它的灵活性和可扩展性,使其成为现代前端开发中不可或缺的工具之一。通过合理配置和使用 Webpack,开发者可以构建高效、可维护的前端应用程序。
webpack中plugin和loader分别做什么?它们之间的执行顺序?
-
loader:用于将不同类型的文件转换成webpack可以识别的文件(webpack只认识js和json)。
-
plugin:存在于webpack整个生命周期中,是一种基于事件机制工作的模式,可以在webpck打包过程对某些节点做某些定制化处理。同时plugin可以对loader解析过程中做一些处理,协同处理文件。
-
执行顺序:两者不存在明显的先后顺序,不过webpack在初始化处理时,会优先识别到plugin中的内容。
拓展
在 Webpack 中,Plugins 和 Loaders 都扮演着重要的角色,但它们的功能和执行时机有所不同。
Loaders
- 功能:
-
Loaders 用于转换或处理模块。它们允许你在
import或load模块时预处理文件。例如,可以将 TypeScript 编译成 JavaScript,将 LESS 编译成 CSS,或者将图像转换为 Data URL。 -
Loaders 可以在 import 语句处转换资源,然后这些资源会被打包进最终的 bundle。
- 执行时机:
- Loaders 在 Webpack 的构建过程中的“转换”步骤中执行,也就是在模块被添加到模块缓存之前。
- 执行顺序:
- Loaders 的执行顺序是从右到左。例如,
sass-loader?sourceMap!css-loader!style-loader会先执行style-loader,然后是css-loader,最后是sass-loader。
Plugins
- 功能:
-
Plugins 用于在 Webpack 构建过程中的特定时机执行更广泛的任务。它们可以影响 Webpack 的构建流程,如优化 bundle 的加载方式、修改输出内容、管理资源、或者提供热重载功能。
-
Plugins 可以监听 Webpack 编译过程中的事件,然后在特定的时机执行自定义逻辑。
- 执行时机:
- Plugins 在 Webpack 的构建过程中的不同阶段执行,例如在开始编译前、编译完成后、每次有文件被添加到 compilation(构建过程)时等。
- 执行顺序:
- Plugins 的执行顺序取决于它们在 Webpack 配置中的定义顺序以及它们监听的事件。例如,
new HtmlWebpackPlugin()可能在构建结束时执行,以便生成一个 HTML 文件。
执行顺序
Webpack 的构建过程大致可以分为以下几个阶段:
-
初始化:Webpack 初始化编译。
-
编译:开始编译过程,包括读取文件、递归解析依赖等。
-
处理:Loaders 被调用,处理文件。
-
优化:Webpack 对编译后的模块进行优化,如压缩、分割代码等。
-
生成:输出最终的 bundle 和资源。
-
输出:将生成的文件写入到文件系统中。
在整个过程中,Plugins 可以在这些阶段的任意时机被触发。而 Loaders 主要集中在“处理”阶段,即在文件被添加到模块缓存之前进行转换。
总的来说,Loaders 负责文件的转换,而 Plugins 负责更广泛的构建流程控制。两者在 Webpack 的构建过程中相辅相成,共同完成资源的加载、转换、优化和输出。
webpack常见的优化方案
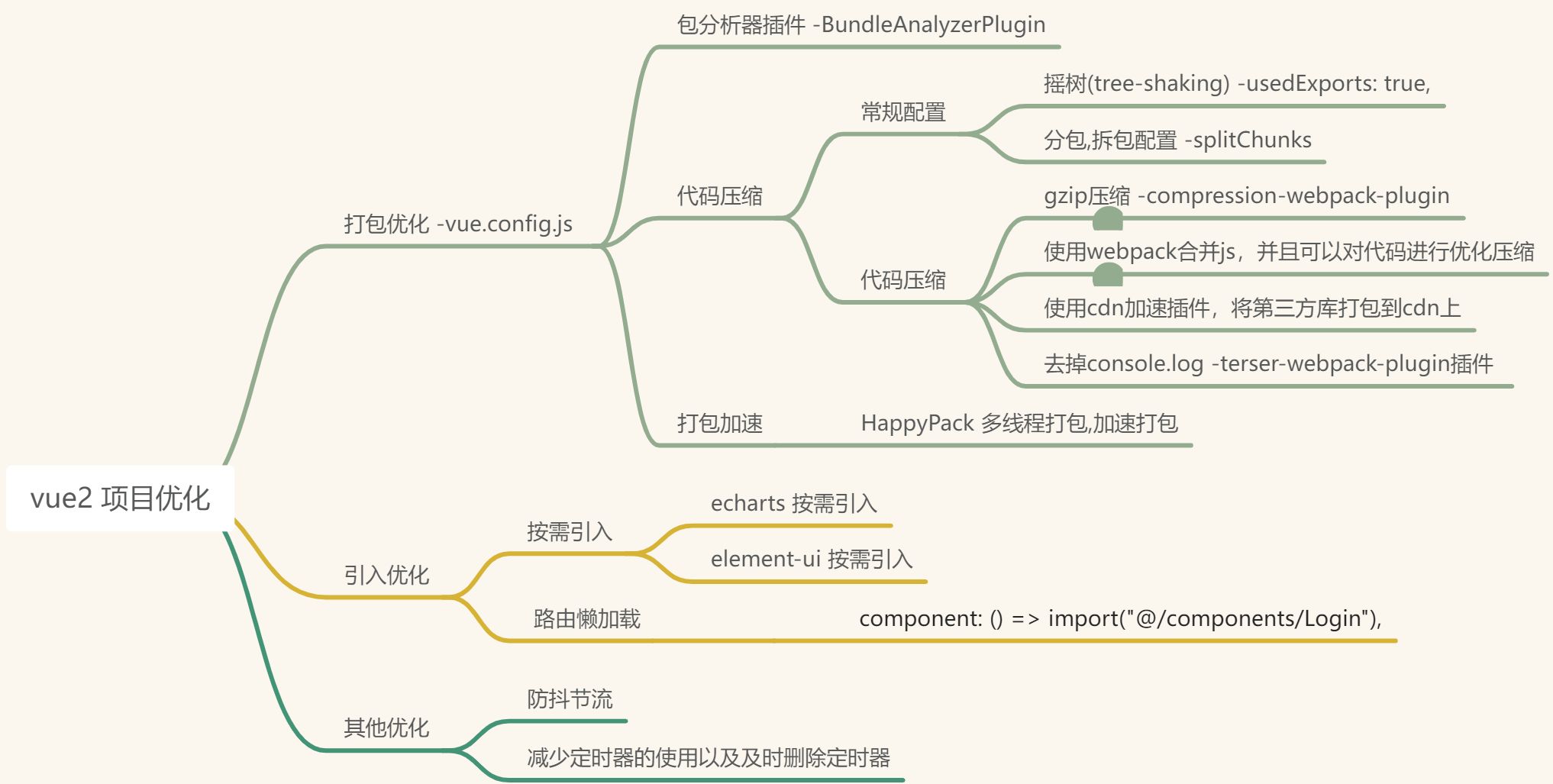
-
基于esm的tree shaking
-
对balel设置缓存,缩小babel-loader的处理范围,及精准指定要处理的目录。
-
压缩资源(mini-css-extract-plugin,compression-webpack-plugin)
-
配置资源的按需引入(第三方组件库)
-
配置splitChunks来进行按需加载(根据)
-
设置CDN优化
关于babel的理解
总结:
将当前平台代码的语法,根据babel.config.js(.balelrc)的配置;转换成目标平台的代码
babel是一个工具链,主要用于将ES2015+代码转换为当前和旧浏览器或环境中向后兼容的Js版本。这句话比较官方,
其实babel就是一个语法转换工具链,它会将我们书写的代码(vue或react)通过相关的解析(对应的Preset),主要是词法解析和语法解析,通过babel-parser转换成对应的AST树,再对得到的抽象语法树根据相关的规则配置,转换成最终需要的目标平台识别的AST树,再得到目标代码。
在日常的Webpack使用主要有三个插件:babel-loader、babel-core、babel-preset-env。 babel本质上会运行babel-loader一个函数,在运行时会匹配到对应的文件,根据babel.config.js(.balelrc)的配置(这里会配置相关的babel-preset-env,它会告诉babel用什么规则去进行代码转换)去将代码进行一个解析和转换(转换依靠的是babel-core),最终得到目标平台的代码。
vite和webpak的区别
vite在开环境时基于ESBuild打包,相比webpack的编译方式,大大提高了项目的启动和热更新速度。
拓展
Vite 和 Webpack 都是现代前端开发中流行的构建工具,但它们在设计理念和性能特点上有所不同。
- 构建速度:
-
Vite 在开发环境中提供了极快的服务器启动和热模块替换(HMR),因为它利用了浏览器原生的 ES 模块特性,不需要预先打包整个应用程序,而是在运行时按需编译和构建代码。这意味着开发者可以体验到几乎即时的反馈,尤其是在大型项目中,Vite 的这一特性比 Webpack 更为显著。
-
Webpack 在开发环境中的启动和热更新速度相对较慢,因为它需要打包所有代码。对于大型项目,Webpack 的这一过程可能需要更长的时间。
- 构建结果:
-
Vite 的构建结果更接近于源代码,因为它是在运行时进行编译和构建的,这使得构建结果更易于调试和排查错误。
-
Webpack 的构建结果则更加优化,它可以将多个文件合并为一个或多个文件,并且可以对这些文件进行压缩和代码分割等优化操作,这有助于提高生产环境下应用程序的加载速度。
- 生态系统和插件:
-
Webpack 拥有一个成熟的生态系统和丰富的插件库,可以扩展其功能,如代码分割、压缩、混淆、静态资源管理等。
-
Vite 的生态系统相对较新,但也在不断发展,提供了一些有用的插件,如 Vite-plugin-Vue、Vite-plugin-React、Vite-plugin-CSS 等。
- 设计理念:
-
Vite 的核心理念是“快速开发”,它采用了一种新颖的实时编译构建方式,可以在开发过程中即时编译和构建代码,以提高开发效率。
-
Webpack 的核心理念是“模块化”,它支持使用各种语言和框架编写模块,并将它们打包成可在浏览器中使用的 JavaScript 文件。
- 配置复杂度:
-
Vite 通常被认为是更简单、更易于配置的工具,它提供了零配置的体验,开箱即用。
-
Webpack 的配置相对复杂,需要配置各种 loader 和 plugin,这可能会对初学者构成一定的学习曲线。
- 生产环境构建:
-
Vite 在生产环境中依赖 Rollup 进行打包,这使得构建过程简单且高效。
-
Webpack 在生产环境中提供了更多的优化和插件选择,适合需要复杂构建流程的项目。
总的来说,Vite 以其快速的开发服务器和现代化的构建方式在开发体验上具有优势,而 Webpack 则在构建优化和生态系统方面更为成熟。开发者可以根据项目需求、团队熟悉度以及对构建速度和生产环境优化的需求来选择适合的工具。
项目相关题
关于模块化
总结:模块化就是将程序拆分成不同的结构,每个小模块内部作用域相对独立,在需要时进行按需导入使用.
首先模块化的目的是将程序划分为一个个小的结构。在这些结构中编写自己的逻辑代码,有自己的作用域,不会影响到其他的结构。同时这些结构可以将自己希望暴露的函数、变量、对象等导出给其他结构使用,也可通过某种方式,将另外结构中的函数、变量、对象等导入使用。
token 可以放在 cookie 里吗?
https://juejin.cn/post/6922782392390746125
方案
Token 放 cookie :cookie 设置 httpOnly,设置 sameSite=Lax,
总结
关于token 存在cookie还是localStorage有两个观点。
-
支持Cookie的开发人员会强烈建议不要将敏感信息(例如JWT)存储在localStorage中,因为它对于XSS毫无抵抗力。
-
支持localStorage的一派则认为:撇开localStorage的各种优点不谈,如果做好适当的XSS防护,收益是远大于风险的。
放在cookie中看似看全,看似“解决”(因为仍然存在XSS的问题)一个问题,却引入了另一个问题(CSRF)
localStorage具有更灵活,更大空间,天然免疫 CSRF的特征。Cookie空间有限,而JWT一半都占用较多字节,而且有时你不止需要存储一个JWT。
不懂什么是JWT的参考阅读【什么是JWT】
当被问这个问题的时候,第一时间要想到安全问题。通常回答不可以,因为存在CSRF(跨站请求伪造)风险,攻击者可以冒用Cookie中的信息来发送恶意请求。解决CSRF问题,可以设置同源检测(Origin和Referer认证),也可以设置Samesite为Strict。最好嘛,就是不把token放在cookie里咯。
CSRF 和 XSS
https://blog.csdn.net/dzqxwzoe/article/details/128917350
https://blog.csdn.net/dzqxwzoe/article/details/128917350
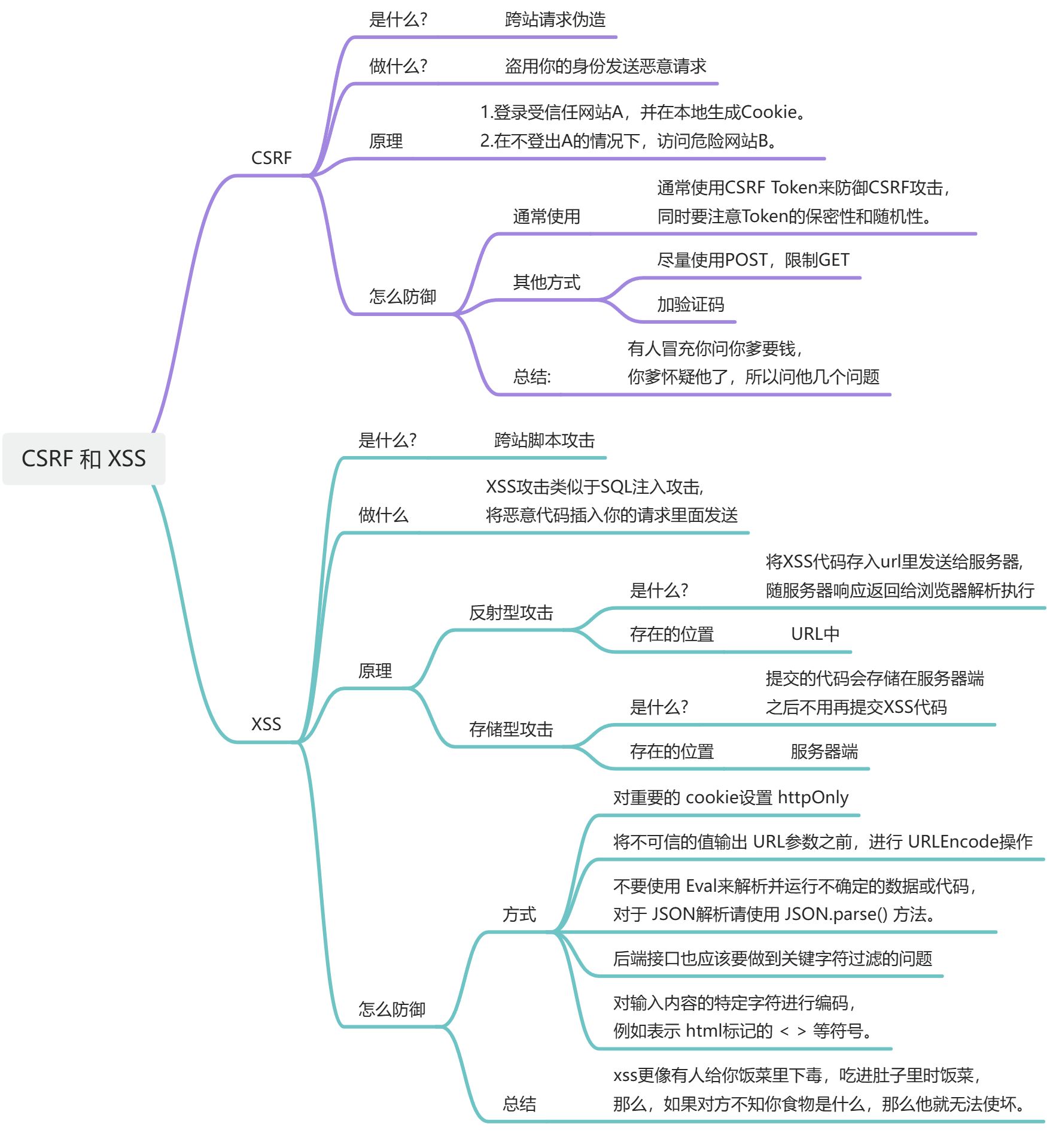
CSRF
- 总结*
CSRF攻击是攻击者利用用户的身份操作用户帐户的一种攻击方式,通常使用Anti CSRF Token来防御CSRF攻击,同时要注意Token的保密性和随机性。
比如:有人冒充你问你爹要钱,你爹怀疑他了,所以问他几个问题,比如你几岁还尿床。用这些问题来判断冒充者是不是你。
一.CSRF是什么?
CSRF(Cross-site request forgery),中文名称:跨站请求伪造,
二.CSRF可以做什么?
- *你这可以这么理解CSRF攻击:攻击者盗用了你的身份,以你的名义发送恶意请求。**CSRF能够做的事情包括:以你名义发送邮件,发消息,盗取你的账号,甚至于购买商品,虚拟货币转账......造成的问题包括:个人隐私泄露以及财产安全。
四.CSRF的原理
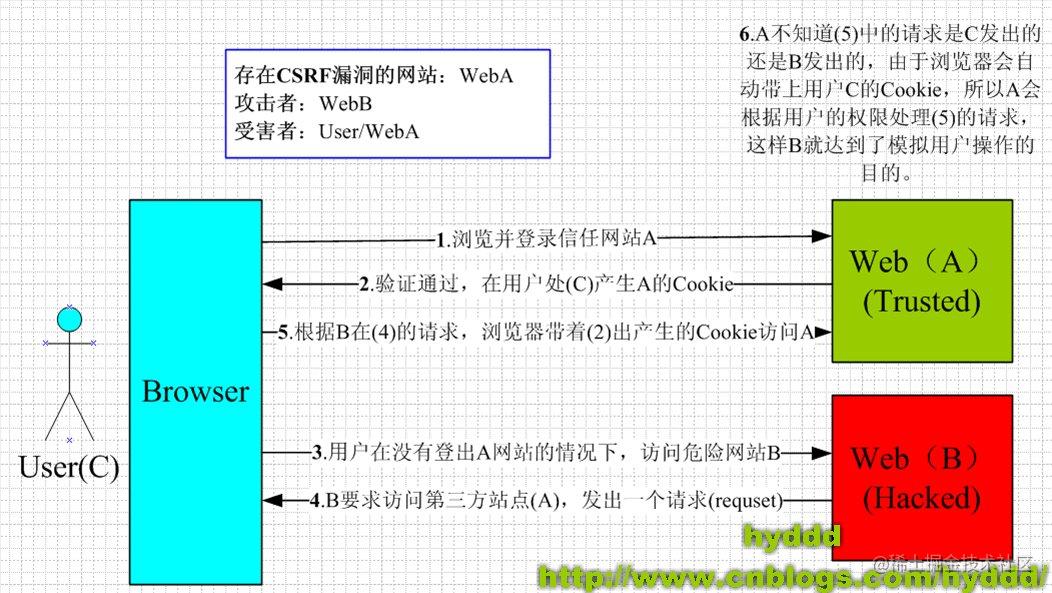
从上图可以看出,要完成一次CSRF攻击,受害者必须依次完成两个步骤:
-
1.登录受信任网站A,并在本地生成Cookie。*
-
* 2.在不登出A的情况下,访问危险网站B。**
看到这里,你也许会说:“如果我不满足以上两个条件中的一个,我就不会受到CSRF的攻击”。是的,确实如此,但你不能保证以下情况不会发生:
-
1.你不能保证你登录了一个网站后,不再打开一个tab页面并访问另外的网站。*
-
* 2.你不能保证你关闭浏览器了后,你本地的Cookie立刻过期,你上次的会话已经结束。(事实上,关闭浏览器不能结束一个会话,但大多数人都会错误的认为关闭浏览器就等于退出登录/结束会话了......)**
-
* 3.上图中所谓的攻击网站,可能是一个存在其他漏洞的可信任的经常被人访问的网站。**
五CSRF防御
- 尽量使用POST,限制GET
GET接口太容易被拿来做CSRF攻击,看第一个示例就知道,只要构造一个img标签,而img标签又是不能过滤的数据。接口最好限制为POST使用,GET则无效,降低攻击风险。
当然POST并不是万无一失,攻击者只要构造一个form就可以,但需要在第三方页面做,这样就增加暴露的可能性。
2**. 浏览器Cookie策略**
IE6、7、8、Safari会默认拦截第三方本地Cookie(Third-party Cookie)的发送。但是Firefox2、3、Opera、Chrome、Android等不会拦截,所以通过浏览器Cookie策略来防御CSRF攻击不靠谱,只能说是降低了风险。
PS:Cookie分为两种,Session Cookie(在浏览器关闭后,就会失效,保存到内存里),Third-party Cookie(即只有到了Exprie时间后才会失效的Cookie,这种Cookie会保存到本地)。
PS:另外如果网站返回HTTP头包含P3P Header,那么将允许浏览器发送第三方Cookie。
- 加验证码
验证码,强制用户必须与应用进行交互,才能完成最终请求。在通常情况下,验证码能很好遏制CSRF攻击。但是出于用户体验考虑,网站不能给所有的操作都加上验证码。因此验证码只能作为一种辅助手段,不能作为主要解决方案。
- Referer Check
Referer Check在Web最常见的应用就是“防止图片盗链”。同理,Referer Check也可以被用于检查请求是否来自合法的“源”(Referer值是否是指定页面,或者网站的域),如果都不是,那么就极可能是CSRF攻击。
但是因为服务器并不是什么时候都能取到Referer,所以也无法作为CSRF防御的主要手段。但是用Referer Check来监控CSRF攻击的发生,倒是一种可行的方法。
5**. Anti CSRF Token**
现在业界对CSRF的防御,一致的做法是使用一个Token(Anti CSRF Token)。
例子:
- 用户访问某个表单页面。2.服务端生成一个Token,放在用户的Session中,或者浏览器的Cookie中。3.在页面表单附带上Token参数。4.用户提交请求后, 服务端验证表单中的Token是否与用户Session(或Cookies)中的Token一致,一致为合法请求,不是则非法请求。这个Token的值必须是随机的,不可预测的。由于Token的存在,攻击者无法再构造一个带有合法Token的请求实施CSRF攻击。另外使用Token时应注意Token的保密性,尽量把敏感操作由GET改为POST,以form或AJAX形式提交,避免Token泄露。
注意:
CSRF的Token仅仅用于对抗CSRF攻击。当网站同时存在XSS漏洞时候,那这个方案也是空谈。所以XSS带来的问题,应该使用XSS的防御方案予以解决。
- 总结*
CSRF攻击是攻击者利用用户的身份操作用户帐户的一种攻击方式,通常使用Anti CSRF Token来防御CSRF攻击,同时要注意Token的保密性和随机性。
比如:有人冒充你问你爹要钱,你爹怀疑他了,所以问他几个问题,比如你几岁还尿床。用这些问题来判断冒充者是不是你。
XSS
总结:xss更像有人给你饭菜里下毒,吃进肚子里时饭菜,但可能还有一些小可爱。那么,如果对方不知你食物是什么,那么他就无法使坏。这就需要把你的饭菜做成黑暗料理,让对方分辨不出这是食物。
XSS又称CSS,全称Cross SiteScript,跨站脚本攻击,是Web程序中常见的漏洞,XSS属于被动式且用于客户端的攻击方式,所以容易被忽略其危害性。其原理是攻击者向有XSS漏洞的网站中输入(传入)恶意的HTML代码,当其它用户浏览该网站时,这段HTML代码会自动执行,从而达到攻击的目的。如,盗取用户Cookie、破坏页面结构、重定向到其它网站等
一:XSS攻击
XSS攻击类似于SQL注入攻击,攻击之前,我们先找到一个存在XSS漏洞的网站,XSS漏洞分为两种,一种是DOM Based XSS漏洞,另一种是Stored XSS漏洞。理论上,所有可输入的地方没有对输入数据进行处理的话,都会存在XSS漏洞,漏洞的危害取决于攻击代码的威力,攻击代码也不局限于script。
1、反射型攻击
发出请求时,XSS代码出现在URL中,作为输入提交到服务器端,服务器解析后响应,XSS代码随响应内容一起传回给浏览器,最后浏览器解析执行XSS代码。这个过程像一次反射,故叫反射型XSS。
明文URL中value就是攻击代码
服务器解析URL中XSS代码并传回
浏览器解析执行
传播-》URL传播-》短网址传播
2、存储型攻击
存储型XSS和反射型XSS的差别仅在于,提交的代码会存储在服务器端(数据库,内存,文件系统等),下次请求目标页面时不用再提交XSS代码。
更隐蔽。
XSS存在的位置
-
反射型——URL中
-
存储型——服务器端
XSS攻击注入点:
-
HTML节点内,通过用户输入动态生成
-
HTML属性,属性是由用户输入
-
JavaScript代码
-
富文本(一大段HTML,有格式)* 富文本得保留HTML,HTML有XSS攻击风险
二:XSS防御
-
对输入内容的特定字符进行编码,例如表示 html标记的 < > 等符号。
-
对重要的 cookie设置 httpOnly, 防止客户端通过document.cookie读取 cookie,此 HTTP头由服务端设置。
-
将不可信的值输出 URL参数之前,进行 URLEncode操作,而对于从 URL参数中获取值一定要进行格式检测(比如你需要的时URL,就判读是否满足URL格式)。
-
不要使用 Eval来解析并运行不确定的数据或代码,对于 JSON解析请使用 JSON.parse() 方法。5.后端接口也应该要做到关键字符过滤的问题。
总结:xss更像有人给你饭菜里下毒,吃进肚子里时饭菜,但可能还有一些小可爱。那么,如果对方不知你食物是什么,那么他就无法使坏。这就需要把你的饭菜做成黑暗料理,让对方分辨不出这是食物。
前端埋点的实现,说说看思路
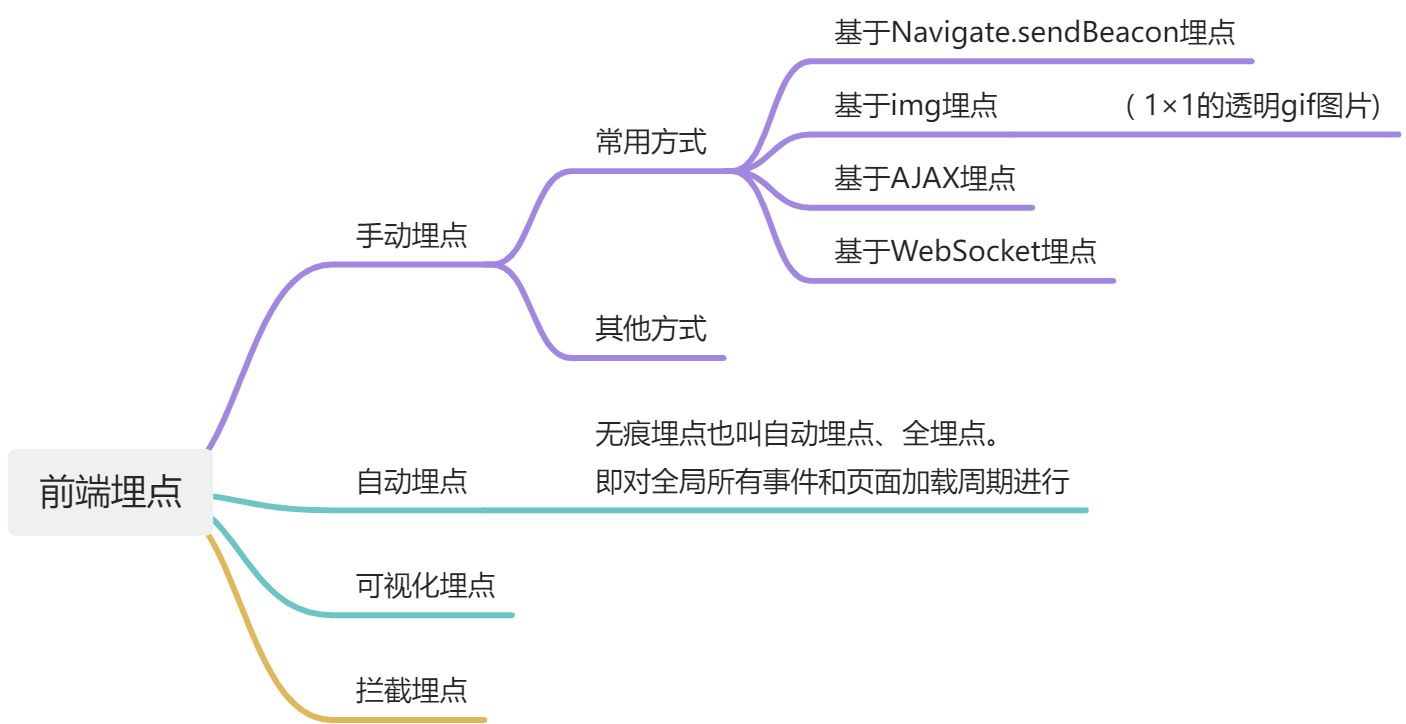
对于埋点方案:一般分为手动埋点(侵入性强,和业务强关联,用于需要精确搜集并分析数据,不过该方式耗时耗力,且容易出现误差,后续要调整,成本较高)、可视化埋点(提供一个可视化的埋点控制台,只能在可视化平台已支持的页面进行埋点)、无埋点(就是全埋点,监控页面发生的一切行为,优点是前端只需要处理一次埋点脚本,不过数据量过大会产生大量的脏数据,需要后端进行数据清洗)。
埋点通常传采用img方式来上传,首先所有浏览器都支持Image对象,并且记录的过程很少出错,同时不存在跨域问题,请求Image也不会阻塞页面的渲染。建议使用1*1像素的GIF,其体积小。
- 现在的浏览器如果支持Navigator.sendBeacon(url, data)方法,优先使用该方法来实现*,它的主要作用就是用于统计数据发送到web服务器。当然如果不支持的话就继续使用图片的方式来上传数据。
说说封装组件的思路
要考虑组件的灵活性、易用性、复用性。 常见的封装思路是,对于视图层面,如相似度高的视图,进行一个封装,提供部分参数方便使用者修改。对于业务复用度较高的,提取出业务组件。
性能优化题
什么情况下会重绘( Repaint) 和回流( Reflow ),常见的改善方案
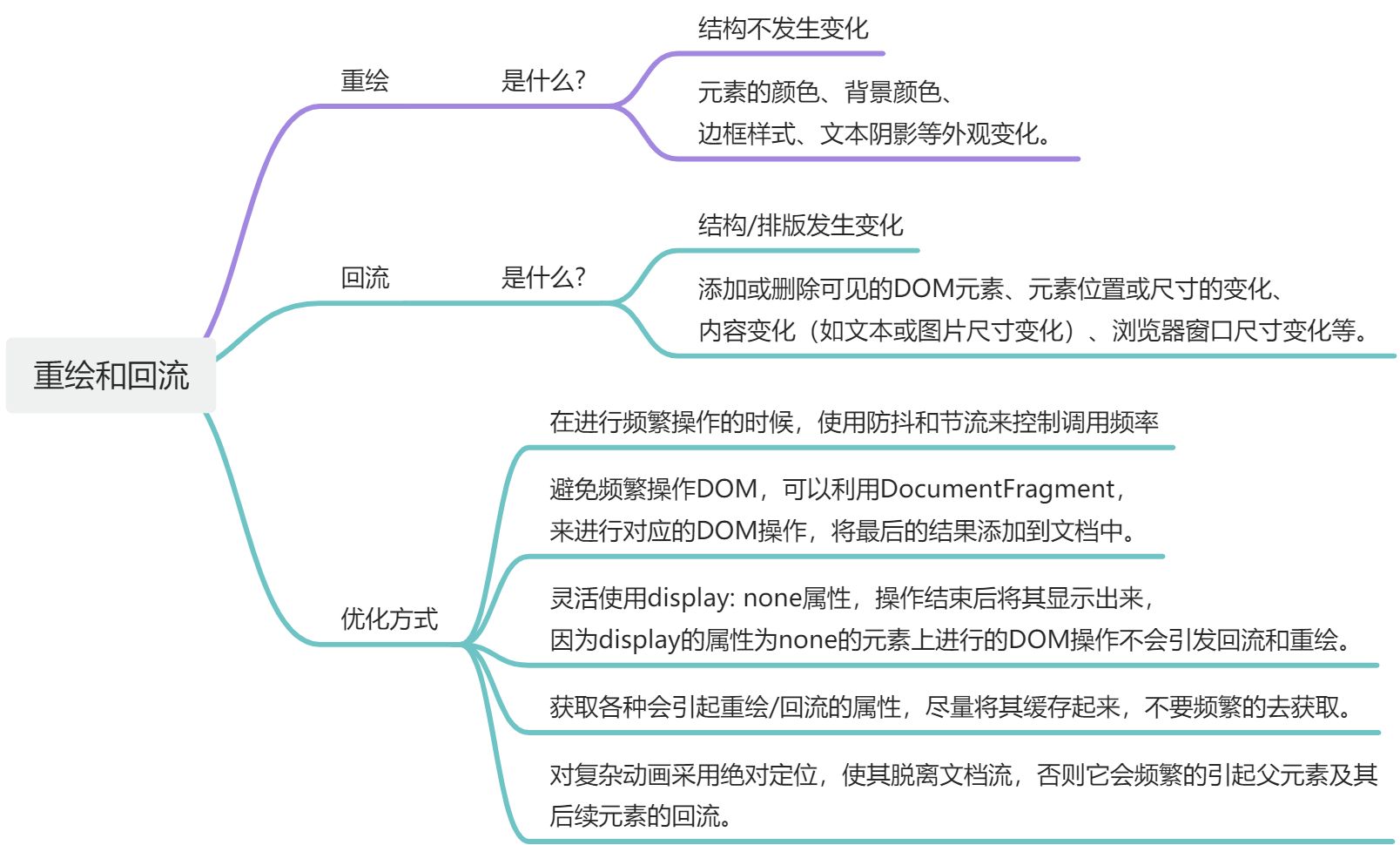
浏览器请求到对应页面资源的时候,会将HTML解析成DOM,把CSS解析成CSSDOM,然后将DOM和CSSDOM合并就产生了Render Tree。在有了渲染树之后,浏览器会根据流式布局模型来计算它们在页面上的大小和位置,最后将节点绘制在页面上。
- 那么当Render Tree中部分或全部元素的尺寸、结构、或某些属性发生改变,浏览器就会重新渲染页面,这个就是浏览器的回流*。常见的回流操作有:页面的首次渲染、浏览器窗口尺寸改变、部分元素尺寸或位置变化、添加或删除可见的DOM、激活伪类、查询某些属性或调用方法(各种宽高的获取,滚动方法的执行等)。
当页面中的元素样式的改变不影响它在文档流的位置时(如color、background-color等),浏览器对应元素的样式,这个就是重绘。
可见:回流必将导致重绘,重绘不一定会引起回流。回流比重绘的代价更高。
常见改善方案:
-
在进行频繁操作的时候,使用防抖和节流来控制调用频率。
-
避免频繁操作DOM,可以利用DocumentFragment,来进行对应的DOM操作,将最后的结果添加到文档中。
-
灵活使用display: none属性,操作结束后将其显示出来,因为display的属性为none的元素上进行的DOM操作不会引发回流和重绘。
-
获取各种会引起重绘/回流的属性,尽量将其缓存起来,不要频繁的去获取。
-
对复杂动画采用绝对定位,使其脱离文档流,否则它会频繁的引起父元素及其后续元素的回流。
一次请求大量数据怎么优化,数据多导致渲染慢怎么优化
https://blog.csdn.net/weixin_43114209/article/details/137229416
https://blog.csdn.net/weixin_43114209/article/details/137229416
大批量接口请求的前端优化是一个复杂而重要的问题。
通过合并请求、
使用防抖和节流、
Web Workers、
缓存请求结果
以及分页和懒加载等技术,
我们可以显著提高应用的性能和用户体验。在实际开发中,需要根据具体场景和需求选择合适的优化策略。