原生
效果展示
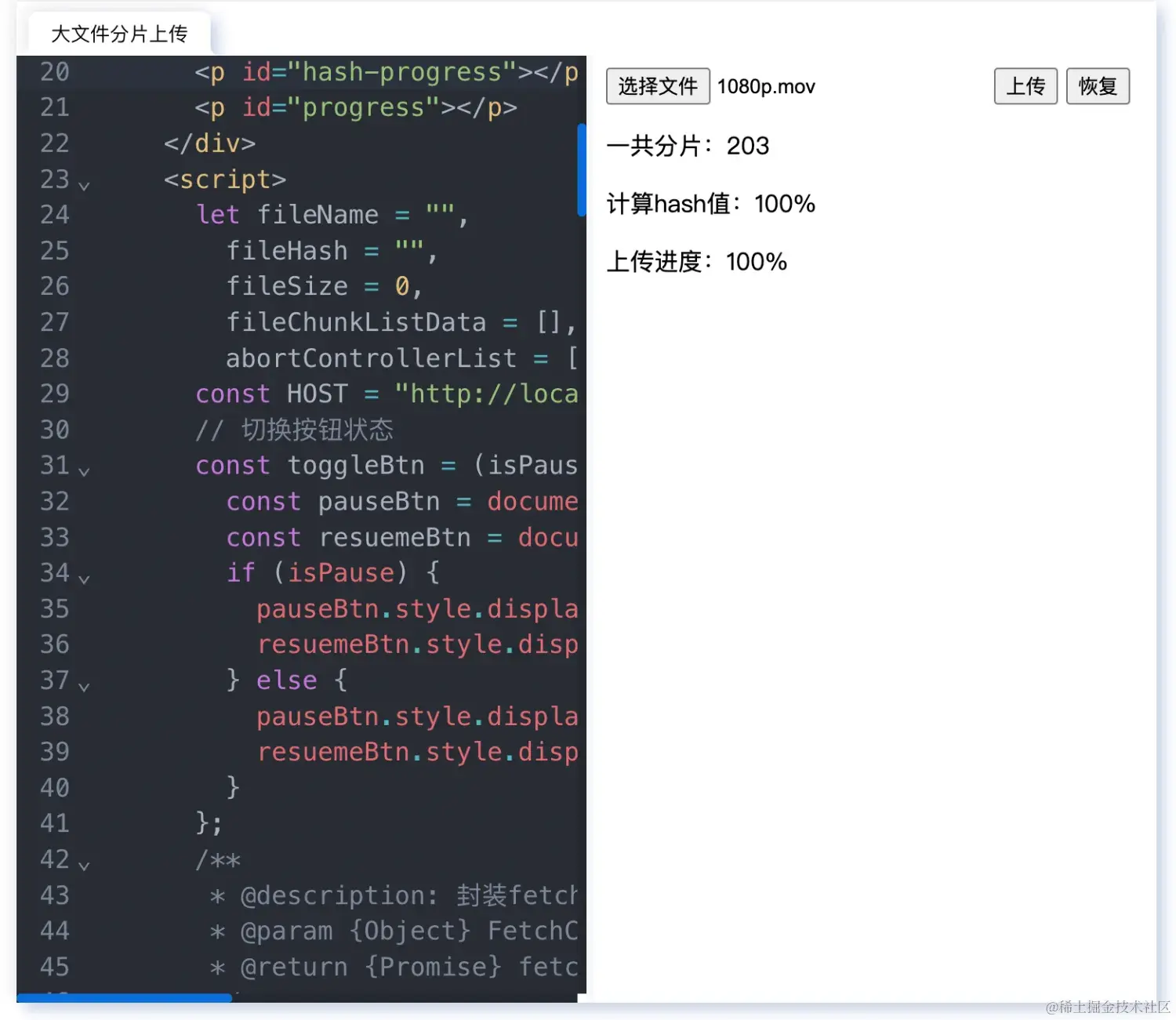
首先来看看最后的效果。
实现思路
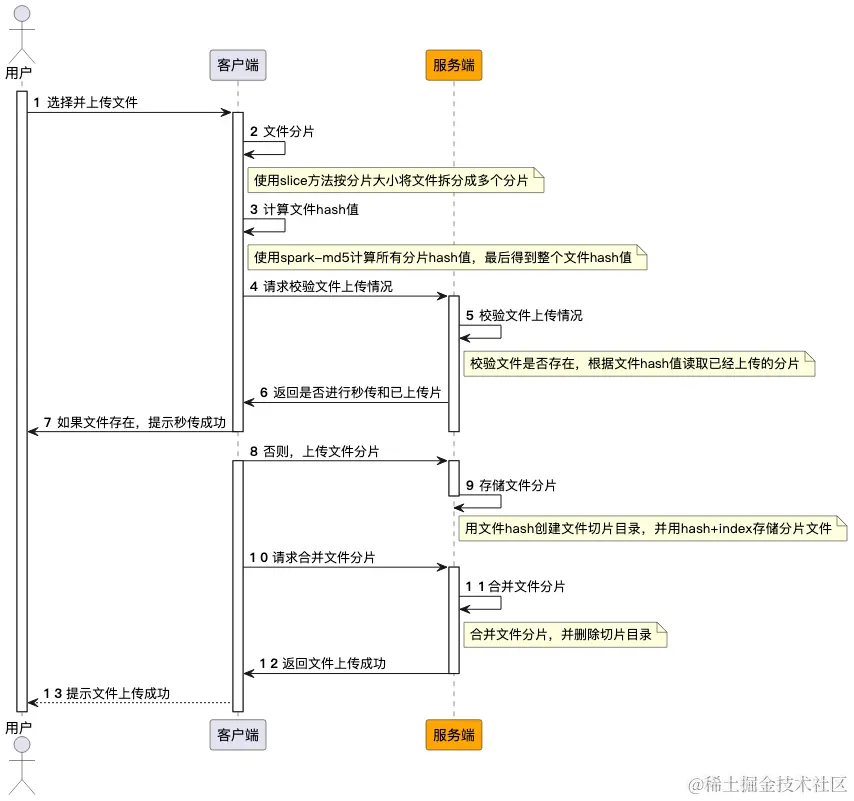
上图是大文件上传的整体流程图,显示了客户端和服务端的交互逻辑,方便大家从宏观上理解大文件上传的过程,但如果按照上面的流程讲解大文件上传入门,很容易被劝退。
下面我们将按照功能点逐步迭代的方式讲解大文件上传,每个功能点都很简单,每实现一个功能点都会极大的增涨我们的信心。大文件上传一共分为分片上传、分片合并、文件秒传、断点续传、上传进度这五个功能点,后面的功能都是在前面的功能基础上迭代完成。如果能实现一个分片上传功能就算是入门了大文件上传了,后面都是在此基础上增加功能而已。
具体实现
分片上传
首先我们来实现一个最简单也最核心的分片上传,这个功能点分为客户端的文件分片、计算hash值、上传分片文件和服务端的创建分片目录并存储分片。客户端和服务端源代码分别存放在BigFileUpload.html 和server.js文件中。
客户端
为了方便后面能够处理取消上传和上传进度,我们首先对fetch 请求做一个简单的封装。
/**
* @description: 封装fetch
* @param {Object} FetchConfig fetch config
* @return {Promise} fetch result
* /
const requestApi = ({
url,
method = "GET",
...fetchProps
}) => {
return new Promise(async (resolve, reject) => {
const res = await fetch(url, {
method,
...fetchProps,
});
resolve(res.json());
});
};
下面是分片功能需要的标签元素。
<input type="file" name="file" id="file" multiple />
<button id="upload" onClick="handleUpload()">上传</button>
<p id="hash-progress"></p>
<p id="total-slice"></p>
首先,我们需要使用slice() 方法对大文件进行分片,并把分片的内容、大小等信息都放入到分片列表中,最后在页面上显示一下分片数量。
- 使用slice方法按分片大小将文件拆分成多个分片*
// 文件分片
const createFileChunk = (file) => {
const chunkList = [];
//计算文件切片总数
const sliceSize = 5 * 1024 * 1024; // 每个文件切片大小定为5MB
const fileSize = file.size; // 修正变量名
const totalSlice = Math.ceil(fileSize / sliceSize);//Math.ceil向上取整
for (let i = 1; i <= totalSlice; i++) {
let chunk;
if (i == totalSlice) {
// 最后一片
chunk = file.slice((i - 1) * sliceSize, fileSize - 1); //切割文件
} else {
chunk = file.slice((i - 1) * sliceSize, i * sliceSize);
}
chunkList.push({
file: chunk,
fileSize,
size: Math.min(sliceSize, file.size),
//size: Math.min(sliceSize, file.size - ((i - 1) * sliceSize))
});
}
const sliceText = `一共分片:${totalSlice}`;
document.getElementById("total-slice").innerHTML = sliceText;
console.log(sliceText);
return chunkList;
};
解释
这段代码是一个JavaScript函数,用于将一个文件分割成多个较小的片段(分片)。下面是对代码的分析和解释:
-
函数
createFileChunk接收一个参数file,这应该是一个File对象。 -
函数内部首先创建了一个空数组
chunkList,用于存储文件的各个切片。 -
定义了
sliceSize为 5MB,这是每个文件切片的大小。 -
计算文件的总切片数
totalSlice,使用Math.ceil确保即使文件大小不能整除切片大小,也会多出一个切片。 -
通过一个
for循环,从1遍历到totalSlice,每个循环迭代都会创建一个新的文件切片。 -
在循环内部,使用
file.slice方法来切割文件。file.slice是一个浏览器API,允许你从文件中提取一部分数据。 -
如果是最后一个切片,使用
fileSize - 1作为结束点,确保不超出文件的边界。 -
每个切片都包含三个属性:
file(切片的Blob对象)、fileSize(切片的原始文件大小)、size(切片的大小)。 -
将创建的切片对象添加到
chunkList数组中。 -
计算完所有切片后,将切片总数显示在页面的
#total-slice元素中。 -
函数返回
chunkList数组,其中包含了所有的文件切片。
注意,这段代码中有几个潜在的问题:
-
fileSize变量没有在函数中定义,应该是file.size。 -
handleUpload函数没有给出,这是点击上传按钮时应该调用的函数。 -
document.getElementById("total-slice").innerHTML = sliceText;这行代码应该在循环外部执行,否则每次循环都会更新页面元素。
然后, 使用spark-md5 分别计算每个分片的hash值,最后得到整个文件hash值。计算hash值需要比较长的时间,可以在页面上输出计算hash值的进度。
- 使用spark-md5计算所有分片hash值,最后得到整个文件hash值*
// 根据分片生成hash
const calculateHash = (fileChunkList) => {
return new Promise((resolve) => {
const spark = new SparkMD5.ArrayBuffer();
let count = 0;
// 计算出hash
const loadNext = (index) => {
const reader = new FileReader(); // 文件阅读对象
reader.readAsArrayBuffer(fileChunkList[index].file);
reader.onload = (e) => {
count++;
spark.append(e.target.result);
if (count === fileChunkList.length) {
resolve(spark.end());
} else {
// 还没读完
const percentage = parseInt(
((count + 1) / fileChunkList.length) * 100
);
const progressText = `计算hash值:${percentage}%`;
document.getElementById("hash-progress").innerHTML =
progressText;
console.log(progressText);
loadNext(count);
}
};
};
loadNext(0);
});
};
web worker 开启线程做这个事
解释
这段代码是一个JavaScript函数 calculateHash,它接收一个包含文件切片的数组 fileChunkList 作为参数,并返回一个 Promise 对象。这个函数的目的是计算每个文件切片的MD5哈希值,并将它们拼接起来以得到整个文件的哈希值。下面是对代码的分析和解释:
-
calculateHash函数使用SparkMD5.ArrayBuffer创建一个新的SparkMD5实例,用于计算哈希值。 -
定义了一个变量
count来跟踪已经处理的文件切片数量。 -
定义了一个内部函数
loadNext,它接收一个参数index,表示当前要处理的文件切片的索引。 -
在
loadNext函数内部,创建了一个FileReader对象,用于读取文件切片的内容。 -
使用
reader.readAsArrayBuffer方法读取当前切片的file属性,该属性是一个Blob对象,将其转换为ArrayBuffer。 -
为
FileReader对象设置onload事件处理器,当文件切片读取完成后触发。 -
在
onload事件处理器中,将读取到的ArrayBuffer添加到SparkMD5实例中,使用spark.append(e.target.result)。 -
检查
count是否等于fileChunkList.length,如果是,则表示所有切片都已处理完毕,调用resolve(spark.end())来解析Promise,并返回最终的哈希值。 -
如果还有切片未处理,更新
count并计算进度百分比,然后更新页面的#hash-progress元素,显示当前的进度。 -
递归调用
loadNext(count)来读取下一个文件切片。 -
最初调用
loadNext(0)来开始处理第一个文件切片。
这段代码使用了递归和异步操作来处理文件切片,并通过 Promise 来管理异步结果。这种方式可以有效地处理大文件,因为它不需要一次性将整个文件加载到内存中。
请注意,这段代码假设 fileChunkList 数组中的每个元素都有一个 file 属性,该属性是一个Blob对象,可以被 FileReader 读取。此外,这段代码没有处理可能发生的错误,例如文件读取失败。在实际应用中,你可能需要添加错误处理逻辑来增强代码的健壮性。
紧接着,需要将分片数据全部上传到服务器,这里需要注意是的分片的hash值是 {index}, 服务端会根据这个hash值创建分片文件。
- 将分片数据全部上传到服务器*
let fileName = "",
fileHash = "",
fileSize = 0,
fileChunkListData = [];
const HOST = "http://localhost:3000";
// ...
const handleUpload = async () => {
const file = document.getElementById("file").files[0];
if (!file) return alert("请选择文件!");
fileName = file.name; // 文件名
fileSize = file.size; // 文件大小
const fileChunkList = createFileChunk(file);
fileHash = await calculateHash(fileChunkList); // 文件hash
fileChunkListData = fileChunkList.map(({ file, size }, index) => {
const hash = `${fileHash}-${index}`;//分片的hash
return {
file,
size,
fileName,
fileHash,
hash,
};
});
await uploadChunks();
};
//上传分片
const uploadChunks = async () => {
const requestList = fileChunkListData
.map(({ file, fileHash, fileName, hash }, index) => {
const formData = new FormData();
formData.append("file", file);
formData.append("fileHash", fileHash);
formData.append("name", fileName);
formData.append("hash", hash);
return { formData };
})
.map(async ({ formData }) => {
return requestApi({
url: `${HOST}`,
method: "POST",
body: formData,
});
});
await Promise.all(requestList);
};
解释
这段代码是一个异步JavaScript函数 handleUpload,它与另一个函数 uploadChunks 一起工作,用于处理文件的上传流程。以下是对代码的详细解释:
-
首先,代码定义了几个全局变量:
fileName、fileHash、fileSize和fileChunkListData。这些变量分别用来存储文件名、文件的哈希值、文件大小和文件切片的数据。 -
HOST变量定义了上传文件的服务器地址。 -
handleUpload函数首先通过document.getElementById("file").files[0]获取用户选择的文件。如果没有选择文件,会弹出警告并退出函数。 -
获取文件后,设置文件名和大小的全局变量。
-
调用
createFileChunk函数将文件分割成多个切片,并将结果存储在全局变量fileChunkList中。 -
使用
await关键字等待calculateHash函数完成,并计算整个文件的哈希值,然后将其存储在fileHash变量中。 -
接下来,使用
map方法处理fileChunkList数组,为每个文件切片创建一个对象,包含文件切片、大小、文件名、文件哈希值和切片的哈希值(这里假设是文件哈希值和切片索引的组合)。 -
将处理后的切片数据存储在
fileChunkListData数组中。 -
最后,调用
uploadChunks函数开始上传过程。 -
uploadChunks函数使用map方法遍历fileChunkListData数组,为每个切片创建一个FormData对象,并添加文件、哈希值、文件名和切片哈希值作为表单数据。 -
然后,再次使用
map方法将每个FormData对象转换为一个异步操作,调用requestApi函数(这个函数没有在代码中定义,应该是一个发送HTTP请求的函数)来上传每个文件切片。 -
使用
Promise.all等待所有上传操作完成。
这段代码展示了如何将文件切片并上传到服务器的过程。不过,代码中有几个潜在的问题和改进点:
-
requestApi函数没有给出定义,你需要确保这个函数存在并且能正确发送HTTP请求。 -
uploadChunks函数中的requestList应该是一个数组,但是在第一次map调用后,它是一个对象数组。你可能需要将这个数组扁平化,或者直接在第二次map调用中处理异步上传。 -
代码中没有错误处理逻辑,实际应用中应该添加错误处理来增强代码的健壮性。
-
代码中的
hash变量是通过对fileHash和切片索引进行字符串连接得到的,这可能不是正确的哈希计算方式。通常,每个切片的哈希应该是基于切片内容独立计算的。
请注意,这段代码只是一个示例,实际使用时需要根据你的具体需求和服务器端点进行调整。
服务端
首先,我们使用原生node.js启动一个后端服务。
import * as http from "http"; //ES 6
import path from "path";
const server = http.createServer();
server.on("request", async (req, res) => {
res.setHeader("Access-Control-Allow-Origin", "*");
res.setHeader("Access-Control-Allow-Headers", "*");
if (req.method === "OPTIONS") {
res.status = 200;
res.end();
return;
}
});
server.listen(3000, () => console.log("正在监听 3000 端口"));
接下来,我们就可以在里面添加上传分片的接口。使用multiparty读取到客户端提交的表单数据后,判断切片目录是否存在,不存在就使用 fileHash 值创建一个临时的分片目录,并使用fs-extra 的****move**** 方法存储文件分片到对应的分片目录下。
import * as http from "http"; //ES 6
import path from "path";
import fse from "fs-extra";
import multiparty from "multiparty";
const server = http.createServer();
const UPLOAD_DIR = path.resolve("/Users/sxg/Downloads/", "target"); // 大文件存储目录
server.on("request", async (req, res) => {
res.setHeader("Access-Control-Allow-Origin", "*");
res.setHeader("Access-Control-Allow-Headers", "*");
if (req.method === "OPTIONS") {
res.status = 200;
res.end();
return;
}
if (req.url === "/") {
const multipart = new multiparty.Form();
multipart.parse(req, async (err, fields, files) => {
if (err) {
console.error(err);
res.status = 500;
res.end(
JSON.stringify({
messaage: "process file chunk failed",
})
);
return;
}
const [chunk] = files.file;
const [hash] = fields.hash;
const [filename] = fields.name;
const [fileHash] = fields.fileHash;
const chunkDir = `${UPLOAD_DIR}/${fileHash}`;
const filePath = path.resolve(
UPLOAD_DIR,
`${fileHash}${extractExt(filename)}`
);
// 文件存在直接返回
if (fse.existsSync(filePath)) {
res.end(
JSON.stringify({
messaage: "file exist",
})
);
return;
}
// 切片目录不存在,创建切片目录
if (!fse.existsSync(chunkDir)) {
await fse.mkdirs(chunkDir);
}
// fs-extra 专用方法,类似 fs.rename 并且跨平台
// fs-extra 的 rename 方法 windows 平台会有权限问题
// https://github.com/meteor/meteor/issues/7852#issuecomment-255767835
await fse.move(chunk.path, `${chunkDir}/${hash}`);
res.status = 200;
res.end(
JSON.stringify({
messaage: "received file chunk",
})
);
});
}
});
server.listen(3000, () => console.log("正在监听 3000 端口"));
解释
这段代码是一个使用Node.js的HTTP服务器的示例,它使用http模块创建了一个服务器,并使用multiparty库来处理多部分表单数据,通常用于文件上传。以下是对代码的分析和解释:
-
首先,代码导入了必要的模块:
http模块用于创建服务器,path模块用于处理文件路径,fs-extra(fse)模块提供了额外的文件系统操作功能,multiparty模块用于解析多部分表单请求。 -
定义了服务器的上传目录
UPLOAD_DIR。 -
创建了一个HTTP服务器实例
server。 -
为服务器设置了CORS(跨源资源共享)相关的响应头,允许跨域请求。
-
定义了一个请求处理函数,当接收到请求时会调用。
-
如果请求的URL是
"/",表示是文件上传请求,创建了一个multiparty.Form实例来解析请求。 -
在
multiparty解析完成后,从解析结果中获取文件、哈希值、文件名和文件哈希值。 -
根据文件哈希值创建一个目录来存储文件切片,如果目录不存在,则使用
fse.mkdirs创建。 -
使用
fse.move方法将上传的文件切片移动到指定目录。这里提到了fse.rename在Windows平台上可能存在权限问题,因此使用了fse.move作为替代。 -
如果文件已经存在,则直接返回一个响应表示文件已存在。
-
服务器监听3000端口,当服务器启动时在控制台打印一条消息。
代码中有几个需要注意的地方:
-
multiparty解析表单数据时,files和fields都是数组,因此使用[chunk]和[...value]来解构获取单个值。 -
fse.move方法用于移动文件,它类似于fs.rename但提供了跨平台支持。然而,根据注释中提到的GitHub问题,使用fse.move可能在某些情况下遇到权限问题,尤其是在Windows上。 -
代码中的
res.end调用使用了错误的属性res.status而不是res.statusCode。应该使用res.status(200).end(...)或者res.end(...)并让http模块默认设置状态码为200。 -
extractExt函数没有在代码中定义,它应该用于从文件名中提取文件扩展名,以便正确保存文件。
请注意,这段代码只是一个示例,可能需要根据你的具体需求进行调整。在实际部署之前,确保测试所有功能,包括文件上传、文件存在性检查、目录创建等。
到这里为止,我们就已经实现了文件上传最基本的功能,后续只是在此基础上进行迭代。
合并分片
客户端
在上传完文件分片之后,我们就可以对所有文件分片进行合并,这里需要请求一个合并分片的接口,需要传递文件的fileHash 和 filename 。
- 上传完毕文件发送合并文件接口指令*
//上传分片
const uploadChunks = async () => {
//...
await mergeRequest(fileName, fileHash);
};
// 合并分片
const mergeRequest = async (fileName, fileHash) => {
await requestApi({
url: `${HOST}/merge`,
method: "POST",
headers: {
"Content-Type": "application/json;charset=utf-8",
},
body: JSON.stringify({
filename: fileName,
fileHash,
}),
});
};
服务端
合并切片功能最核心的功能就是根据fileHash读取对应分片目录下的分片文件列表,并按照分片下标进行排序,避免后面合并时顺序错乱。然后,使用 writeFile 方法创建一个空文件,再使用appendFileSync 依次向文件中添加分片数据,最后删除临时的分片目录。
// 合并切片
const mergeFileChunk = async (filePath, fileHash) => {
const chunkDir = `${UPLOAD_DIR}/${fileHash}`;
const chunkPaths = await fse.readdir(chunkDir);
// 根据切片下标进行排序,否则直接读取目录的获得的顺序可能会错乱
chunkPaths.sort((a, b) => a.split("-")[1] - b.split("-")[1]);
await fse.writeFile(filePath, "");
chunkPaths.forEach((chunkPath) => {
fse.appendFileSync(filePath, fse.readFileSync(`${chunkDir}/${chunkPath}`));
fse.unlinkSync(`${chunkDir}/${chunkPath}`);
});
fse.rmdirSync(chunkDir); // 合并后删除保存切片的目录
};
这里实现一下合并分片的接口,首先需要读取请求中的数据,然后拼接出合并后的文件名称 {fileHash}${ext},最后调用合并分片方法。
import * as http from "http"; //ES 6
import path from "path";
import fse from "fs-extra";
import multiparty from "multiparty";
const server = http.createServer();
const extractExt = (filename) =>
filename.slice(filename.lastIndexOf("."), filename.length); // 提取后缀名
//...
const resolvePost = (req) =>
new Promise((resolve) => {
let chunk = "";
req.on("data", (data) => {
chunk += data;
});
req.on("end", () => {
resolve(JSON.parse(chunk));
});
});
server.on("request", async (req, res) => {
//...
if (req.url === "/merge") {
const data = await resolvePost(req);
const { filename, fileHash } = data;
const ext = extractExt(filename);
const filePath = `${UPLOAD_DIR}/${fileHash}${ext}`;
await mergeFileChunk(filePath, fileHash);
res.status = 200;
res.end(JSON.stringify("file merged success"));
}
});
server.listen(3000, () => console.log("正在监听 3000 端口"));
秒传
客户端
实现秒传只需要在文件上传之前请求接口验证一下文件是否存在。
const handleUpload = async () => {
//...
const { shouldUpload } = await verifyUpload(
fileName,
fileHash
);
if (!shouldUpload) {
alert("秒传:上传成功");
return;
}
//...
};
//文件秒传
const verifyUpload = async (filename, fileHash) => {
const data = await requestApi({
url: `${HOST}/verify`,
method: "POST",
headers: {
"Content-Type": "application/json;charset=utf-8",
},
body: JSON.stringify({
filename,
fileHash,
}),
});
return data;
};
服务端
如果文件存在shouldUpload 就返回 false,否则就返回 true 。
import * as http from "http"; //ES 6
import path from "path";
import fse from "fs-extra";
import multiparty from "multiparty";
const server = http.createServer();
//...
server.on("request", async (req, res) => {
//...
if (req.url === "/verify") {
const data = await resolvePost(req);
const { fileHash, filename } = data;
const ext = extractExt(filename);
const filePath = `${UPLOAD_DIR}/${fileHash}${ext}`;
if (fse.existsSync(filePath)) {
res.end(
JSON.stringify({
shouldUpload: false,
})
);
} else {
res.end(
JSON.stringify({
shouldUpload: true,
})
);
}
}
});
server.listen(3000, () => console.log("正在监听 3000 端口"));
断点续传
客户端
断点续传新增了两个按钮,来控制文件上传进度。
/* ... */
<button id="pause" onClick="handlePause()" style="display: none">
暂停
</button>
<button id="resume" onClick="handleResume()" style="display: none">
恢复
</button>
/* ... */
这里需要对requestApi 进行一些改造,添加 abortControllerList 用于存储需要被取消的请求,如果接口请求成功,则将fetch从 abortControllerList 中移除。
/**
* @description: 封装fetch
* @param {Object} FetchConfig fetch config
* @return {Promise} fetch result
* /
const requestApi = ({
url,
method = "GET",
onProgress,
...fetchProps
}) => {
const controller = new AbortController();
abortControllerList.push(controller);
return new Promise(async (resolve, reject) => {
const res = await fetch(url, {
method,
...fetchProps,
signal: controller.signal,
});
// 将请求成功的 fetch 从列表中删除
const aCIndex = abortControllerList.findIndex(
(c) => c.signal === controller.signal
);
abortControllerList.splice(aCIndex, 1);
//...
});
};
在分片上传也需要做一些改造,将接口中获取到的uploadedList ,从所有分片列表中过滤出去,当已上传的uploadedList 数量加 requestList 的数量等于分片列表fileChunkListData 的数量时才进行分片合并。
let fileName = "",
fileHash = "",
fileSize = 0,
fileChunkListData = [],
abortControllerList = [];
const HOST = "http://localhost:3000";
//...
const handleUpload = async () => {
//...
const { shouldUpload, uploadedList } = await verifyUpload(
fileName,
fileHash
);
if (!shouldUpload) {
alert("秒传:上传成功");
return;
}
//...
await uploadChunks(uploadedList);
};
//上传分片
const uploadChunks = async (uploadedList) => {
const requestList = fileChunkListData
.filter(({ hash }) => !uploadedList.includes(hash))
.map(({ file, fileHash, fileName, hash }, index) => {
//...
})
.map(async ({ formData, hash }) => {
. //...
});
//...
// 之前上传的切片数量 + 本次上传的切片数量 = 所有切片数量时
//合并分片
if (
uploadedList.length + requestList.length ===
fileChunkListData.length
) {
await mergeRequest(fileName, fileHash);
}
};
然后,实现一下暂停和恢复的事件处理,暂停是通过调用 AbortController 的 abort() 方法实现。恢复则是重新获取uploadedList 后再进行分片上传实现。
//暂停
const handlePause = () => {
abortControllerList.forEach((controller) => controller?.abort());
abortControllerList = [];
};
// 恢复
const handleResume = async () => {
const { uploadedList } = await verifyUpload(fileName, fileHash);
await uploadChunks(uploadedList);
};
这段代码是一个文件上传流程的JavaScript实现,包括暂停和恢复上传的功能。以下是对代码的详细解释:
-
封装的Fetch函数 (
requestApi): 这个函数接收一个配置对象,包括URL、HTTP方法、进度回调等,并返回一个Promise。它使用AbortController来支持请求的取消功能。abortControllerList用于存储所有的AbortController实例,以便可以全局控制取消。 -
全局变量: 定义了文件名(
fileName)、文件哈希值(fileHash)、文件大小(fileSize)、文件分片数据列表(fileChunkListData)、AbortController列表(abortControllerList)和服务器主机地址(HOST)。 -
文件上传处理 (
handleUpload): 这个函数首先调用verifyUpload函数来检查文件是否已经部分上传,如果是,则不需要重新上传这些部分。然后调用uploadChunks函数上传剩余的文件切片。 -
上传文件切片 (
uploadChunks): 这个函数使用filter和map方法来创建上传任务列表,只上传那些不在已上传列表中的切片。上传过程中可能包括设置请求头、处理文件分片等。 -
暂停上传 (
handlePause): 这个函数遍历abortControllerList,调用每个AbortController的abort方法来取消所有正在进行的上传请求,并将列表清空。 -
恢复上传 (
handleResume): 这个函数再次调用verifyUpload来获取最新的已上传列表,并使用uploadChunks函数继续上传剩余的文件切片。
代码中有几个关键点需要注意:
-
requestApi函数中的onProgress回调没有在示例中实现,但它可以用来处理上传进度。 -
uploadChunks函数中的map调用似乎不完整,应该包含使用requestApi或其他HTTP请求方法来实际发送文件切片的代码。 -
在
uploadChunks函数中,有一个条件判断用于确定是否需要合并文件切片。这个逻辑需要根据实际的服务器端点和逻辑来实现。 -
handlePause函数中的forEach循环使用了可选链操作符?.,这是ES2020引入的特性,确保不会因为controller未定义而抛出错误。 -
handleResume函数中再次调用verifyUpload和uploadChunks,这意味着在实际使用中,这些函数需要能够处理恢复上传的逻辑。
这段代码提供了一个基本的框架,但在实际部署之前,需要确保所有功能都经过充分测试,并且服务器端点能够正确处理上传的文件切片和合并操作。此外,还需要实现错误处理和进度反馈机制,以提供更好的用户体验。
服务端
断点续传是在秒传接口的基础上实现的,只是需要新增已上传分片列表uploadedList 。
import * as http from "http"; //ES 6
import path from "path";
import fse from "fs-extra";
import multiparty from "multiparty";
const server = http.createServer();
//...
// 返回已经上传切片名列表
const createUploadedList = async (fileHash) =>
fse.existsSync(`${UPLOAD_DIR}/${fileHash}`)
? await fse.readdir(`${UPLOAD_DIR}/${fileHash}`)
: [];
server.on("request", async (req, res) => {
//...
if (req.url === "/verify") {
const data = await resolvePost(req);
const { fileHash, filename } = data;
const ext = extractExt(filename);
const filePath = `${UPLOAD_DIR}/${fileHash}${ext}`;
if (fse.existsSync(filePath)) {
res.end(
JSON.stringify({
shouldUpload: false,
})
);
} else {
res.end(
JSON.stringify({
shouldUpload: true,
uploadedList: await createUploadedList(fileHash),
})
);
}
}
});
server.listen(3000, () => console.log("正在监听 3000 端口"));
上传进度
上传进度只需要改造客户端,首先,新增显示进度的标签。
<p id="progress"></p>
上传进度需要对fetch请求再做一点改造,这里需要使用getReader() 手动读取数据流,获取到当前上传进度,并添加onProgress 回调。
/**
* @description: 封装fetch
* @param {Object} FetchConfig fetch config
* @return {Promise} fetch result
* /
const requestApi = ({
url,
method = "GET",
onProgress,
...fetchProps
}) => {
//...
return new Promise(async (resolve, reject) => {
const res = await fetch(url, {
method,
...fetchProps,
});
const total = res.headers.get("content-length");
const reader = res.body.getReader(); //创建可读流
const decoder = new TextDecoder();
let loaded = 0;
let data = "";
while (true) {
const { done, value } = await reader.read();
loaded += value?.length || 0;
data += decoder.decode(value);
onProgress && onProgress({ loaded, total });
if (done) {
break;
}
}
//...
resolve(JSON.parse(data));
});
};
然后,在上传的时候将已上传进度设置成100,并添加onProgress回调处理,累计每个分片的进度,得到整体的上传进度。
let fileName = "",
fileHash = "",
fileSize = 0,
fileChunkListData = [],
abortControllerList = [];
const HOST = "http://localhost:3000";
//...
const handleUpload = async () => {
//...
fileChunkListData = fileChunkList.map(({ file, size }, index) => {
//...
return {
percentage: uploadedList.includes(hash) ? 100 : 0,
};
});
//...
};
//上传分片
const uploadChunks = async (uploadedList) => {
const requestList = fileChunkListData
.filter(({ hash }) => !uploadedList.includes(hash))
.map(({ file, fileHash, fileName, hash }, index) => {
//...
})
.map(async ({ formData, hash }) => {
return requestApi({
url: `${HOST}`,
method: "POST",
body: formData,
onProgress: ({ loaded, total }) => {
const percentage = parseInt((loaded / total) * 100);
// console.log("分片上传百分比:", percentage);
const curIndex = fileChunkListData.findIndex(
({ hash: h }) => h === hash
);
fileChunkListData[curIndex].percentage = percentage;
const totalLoaded = fileChunkListData
.map((item) => item.size * item.percentage)
.reduce((acc, cur) => acc + cur);
const totalPercentage = parseInt(
(totalLoaded / fileSize).toFixed(2)
);
const progressText = `上传进度:${totalPercentage}%`;
document.getElementById("progress").innerHTML = progressText;
console.log(progressText);
},
});
});
//...
};
总结
大文件上传其实很多时候不需要我们自己去实现,因为已经有很多成熟的解决方案。
但深入理解大文件上传背后的原理,更加有利于我们对已有的大文件上传方案进行个性化改造。
在线实现大文件上传的过程中使用到了三个插件,multiparty、fs-extra、spark-md5,如果大家不太理解,需要自己去补充一下相关知识。
以上就是使用纯原生JS实现大文件分片上传的详细内容,更多关于JS大文件分片上传的资料请关注脚本之家其它相关文章!